# Einführung
首先我们需要先明确为什么需要文件系统:
- 进程在运行期间只能使用其虚拟地址空间来存储数据:容量有限。
- 当进程结束时,其虚拟地址空间中的数据会丢失:无法实现持久的、长期的数据存储。
- 在虚拟进程地址空间中存储数据只允许有限的共享访问:不能实现同时并行使用。
所以我们需要文件系统来提供更高级别,更持久、更可靠并且可共享的数据存储功能。
也就意味着我们会对文件系统有着以下要求:
-
提供存储空间以容纳大量数据(Speicherplatz für (sehr) große Datenmengen bereitstellen)
-
防止数据丢失(Datenverlust vermeiden)
-
支持并发访问数据(Nebenläufigen Zugriff auf Daten ermöglichen)
多个进程应能够同时访问数据。
文件系统的基本作用是将硬盘上的原始数据块组织成结构良好的文件,使得用户和程序可以方便地存取数据。
具体的任务包括:
- 可以描述文件的数据结构(Datenstrukturen zur Beschreibung von Dateien)
- 实现文件(Implementierung der Dateien)
- 命名(Benennung)
- 允许访问文件(Zugriffe auf Dateien ermöglichen)
- 防止未授权访问(Schutz vor unberechtigten Zugriffen)
常见的文件系统有:
-
FAT-16/32 (DOS)
老式的微软文件系统
-
NTFS (Windows NT)
微软当前主流的文件系统
-
Ext2/3/4 (Linux)
Linux 系统中广泛使用的文件系统系列(Ext4 是目前主流)
# 硬盘
硬盘作为长期存储的媒介,可以被看作是一串固定大小的线性数据块序列( eine lineare Sequenz von Blöcken fester Größe )。这里的块(Block)就是硬盘读写的基本单位(Einheit)。这里的块的大小是由操作系统决定的,和硬盘的 sector 没有直接的大小关系。
而为了更好的管理硬盘的存储空间,我们需要操作系统对硬盘属性进行虚拟化,也就是所谓的文件概念(Datei-Konzept):
- 文件是逻辑上的管理单元。(Dateien sind logische Verwaltungs-Einheiten)
- 文件可以持久地存储任意信息。(Dateien speichern beliebige Informationen persistent (dauerhaft))
- 文件系统对块的存储位置、空闲状态等进行了抽象处理。(Datei abstrahiert davon, wo die Blöcke gespeichert sind, welche Blöcke frei sind usw.)
- 进程可以通过系统调用来创建、写入、读取和删除文件。(erstellen, schreiben, lesen, löschen)
- 文件不仅被用户程序使用,也被系统软件使用。( Dateien werden sowohl von Benutzerprogrammen als auch von der Systemsoftware verwendet)
# 文件 (Dateien)
我们首先通过用户视角来了解一下文件系统:就从我们日常接触的文件开始。
文件作为被管理的单位(zu verwaltende Einheiten),可以被不同的进程使用。所有文件都必须有名字,没有统一的命名规则。一般情况下名字会由 2 部分组成:名字(Name)和扩展名(Extension)。而有些系统(比如说 Windows)会解析扩展名,有些则不会(比如 UNIX)。
文件可以采用三种不同的结构方式:
-
非结构化(Unstrukturiert)
操作系统只把文件当作一串字节(eine Folge von Bytes)(适用于 UNIX 和 Windows)来看待,它不会尝试去理解文件里面到底是什么内容。
优点:用户程序有更大的灵活性
-
固定大小记录的序列(Sequenzen von Einträgen fester Größe)
每条记录有固定的大小和结构,比如每行只能写 80 个字符。现代的操作系统已经很少使用这种方式了。
- 具有不同大小记录的树结构(Ein Baum mit Einträgen unterschiedlicher Größe)
每条记录都有一个 Key,这些 Key 都是有序存储的。适合在大型计算机的操作系统(Großrechner-BS )中用于处理大量数据。
# 文件类型(Dateitypen)
操作系统支持多种文件类型:
-
普通文件( Dateien,regular files):
包含用户数据的文件,比如说:
- 文本文件(Text-Dateien): Bestehen aus Zeilen, die durch carriage return (回车符,
\rund/oder linefeed Zeichen(换行符,\nabgeschlossen sind. - 二进制文件(Binärdateien):具有特定格式,比如说可执行文件、压缩包等。
- 文本文件(Text-Dateien): Bestehen aus Zeilen, die durch carriage return (回车符,
-
目录(Verzeichnisse,directories):
是用于组织和管理文件系统中结构的系统文件。
-
块设备文件(Block Special Files)
-
字符设备文件(Character Special Files)
在 linux 种可以用 ls -l 来查看文件类型:
| 第一位字符 | 文件类型 |
|---|---|
| - | 普通文件 |
| d | 目录 |
| c | 块设备文件 |
| b | 字符设备文件 |
例子:
drwxr-xr-x 2 user user 4096 Mar 26 test_folder
-rw-r--r-- 1 user user 1234 Mar 26 notes.txt
crw-rw---- 1 root tty 4, 0 Mar 26 /dev/tty0
brw-rw---- 1 root disk 8, 0 Mar 26 /dev/sda
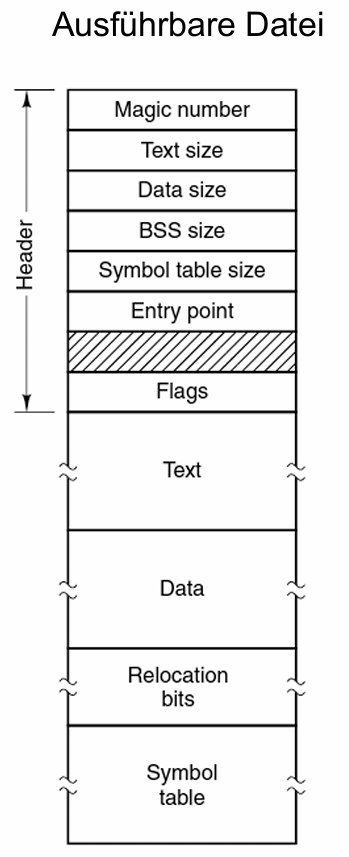
可执行文件的结构:
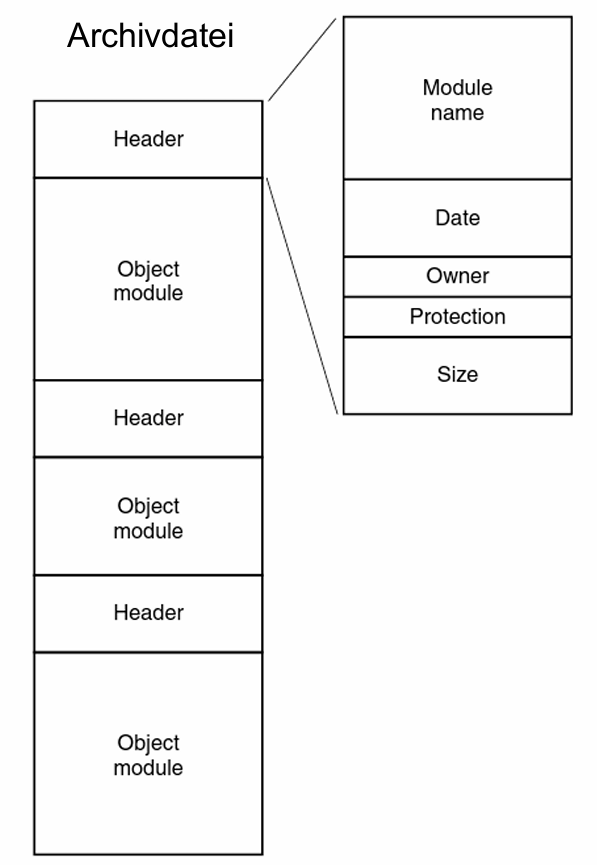
压缩文件的结构:
# 文件访问方式(Dateizugriff)
# 顺序访问(Sequential access)
(只有在很老的操作系统里才会出现了。)
在这种访问下,进程需要按顺序读取文件中的字节(或记录),文件的部分内容不能跳过,适合磁带类存储设备。
比如说读一本书的时候只能一页一页往后翻,不能直接跳到第 50 页。
# 随机访问(Random-access)
进程可以按任意顺序读取文件中的字节(或记录),在数据库系统中尤其重要(快速定位记录)。
UNIX 系统中, lseek 系统调用可以改变 “读写指针” 位置:
lseek(fd, 1024, SEEK_SET); |
fd 是文件描述符,1024 是偏移量(offset)(单位是 Byte),SEEK_SET 则是定位方式,有几种选择:
| 常量名 | 含义 |
|---|---|
| SEEK_SET | 从文件开头开始偏移 offset 字节 |
| SEEK_CUR | 从当前位置开始偏移 |
| SEEK_END | 从文件末尾开始偏移 (offset 需要调整为负数) |
例子:
#include <fcntl.h> | |
#include <unistd.h> | |
#include <stdlib.h> | |
#include <stdio.h> | |
int main(int argc, char *argv[]) { | |
int fd; // 文件描述符 | |
char buf[128]; // 缓冲区,用于读取 128 字节内容 | |
// 打开文件 "myfile.txt",只读方式 | |
fd = open("myfile.txt", O_RDONLY); | |
if (fd < 0) // 如果打开失败,退出 | |
return EXIT_FAILURE; | |
// 将文件读写位置移动到从文件头开始的第 1024 个字节 | |
if (lseek(fd, 1024, SEEK_SET) < 0) | |
return EXIT_FAILURE; | |
// 从当前位置读取 128 字节到缓冲区 buf 中 | |
if (read(fd, buf, 128) < 0) | |
return EXIT_FAILURE; | |
// 打印读取到的内容 | |
printf("%s\n", buf); | |
// 关闭文件 | |
close(fd); | |
// 正常退出 | |
return EXIT_SUCCESS; | |
} |
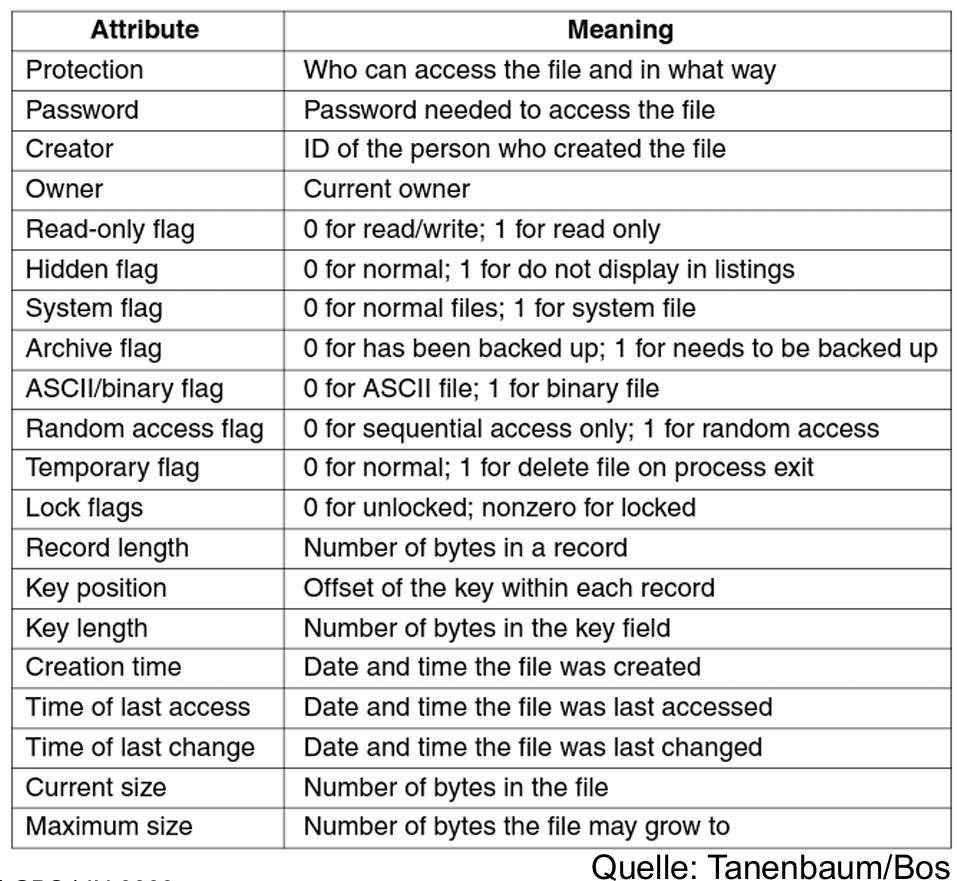
# 文件属性(Dateiattribute)
每份文件除了文件名和文件内容外还会附带一些其他信息:元信息(Meta-Informationen)。
元信息包含:
-
对文件的访问权限
比如说在 UNIX 里,权限赋予对象分成 所有者(Owner)、用户组(Group)、所有人(All)。而权限种类有 r(读取)、w(写入)、x(执行)
例子:
-rwxr--r-- -
标志位(flags):控制文件的某些属性
比如说可以将文件设置为隐藏、标识为二进制或归档文件等。
详见:
# 文件操作(Datei-Operationen)
常见的文件操作都是通过系统调用提供的:
-
创建和删除文件
-
open(打开):在访问一个文件之前,必须先打开它。这会让操作系统把文件属性和其他信息加载到内存中,方便快速处理。
open()系统调用返回一个文件描述符(file descriptor),这是一个小的整数,用来标识这个打开的文件。 -
unlink(删除)
-
-
后续对文件的访问(通过文件描述符)
-
close(关闭)使用文件描述符来关闭文件,释放内部数据结构资源。
-
read(读取)指定要读取的数据以及一个缓冲区(buffer),读取的内容将被放入该缓冲区。
一定要提前创建一个缓冲区!
-
write(写入)将数据写入到当前文件指针所在的位置,注意原有数据可能会被覆盖。
-
seek(定位)移动文件指针到指定位置(之后可以从该位置读取或写入)。(见上面随机访问那里的例子)
-
代码例子:
#include <stdlib.h> | |
#include <fcntl.h> // 包含 open () 的相关定义和文件权限 | |
#include <unistd.h> // 包含 read (), write (), close () 的声明 | |
#define BUF_SIZE 4096 // 定义缓冲区的大小 | |
int main (int argc, char *argv[]) { | |
int fd_in, fd_out, count; // 2 个文件描述符 和 读写字节数计数器 | |
char buf[BUF_SIZE]; // 缓冲区 | |
// 如果参数个数不为 3(程序名 + 输入文件 + 输出文件),则失败退出 | |
if (argc != 3) return EXIT_FAILURE; | |
// 打开输入文件,只读模式(O_RDONLY) | |
if ((fd_in = open(argv[1], O_RDONLY)) == -1) | |
return EXIT_FAILURE; | |
// 打开或创建输出文件,只写模式,权限为用户可读写(rw- --- ---) | |
if ((fd_out = open(argv[2], O_WRONLY | O_CREAT, S_IRUSR | S_IWUSR)) == -1) | |
return EXIT_FAILURE; | |
// 读取输入文件的内容并写入到输出文件中,直到读完 | |
while ((count = read(fd_in, buf, BUF_SIZE)) > 0) { | |
// 如果写入失败或未能写入全部内容,返回失败 | |
if (write(fd_out, buf, count) <= 0) | |
return EXIT_FAILURE; | |
} | |
// 关闭两个文件描述符 | |
close(fd_in); | |
close(fd_out); | |
return EXIT_SUCCESS; // 成功结束程序 | |
} |
# 目录(Verzeichnisse)
文件系统通过目录来组织文件。而目录本质上是一个特殊的文件,它只包含管理信息(比如:文件名、路径、指针等)。目录使文件系统支持层级管理(hierarchische Verwaltung),让结构更清晰、查找更高效。
下面这两种是比较常见的目录结构:
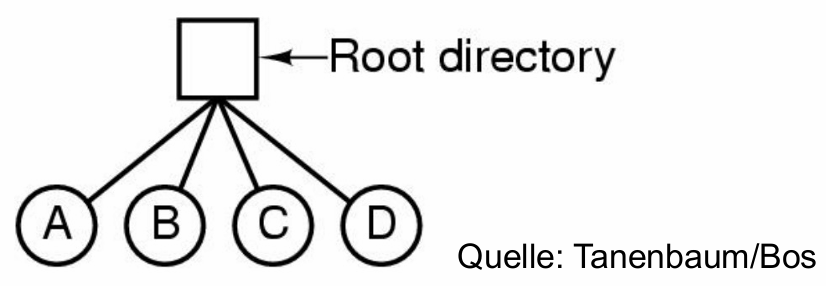
1. 单层目录结构(Single-Level Verzeichnisstrukturen)
在这种结构里只有一个目录(根目录,root directory)用于存放所有文件。目前依然在一些嵌入式系统中使用。
优点:文件可以很快被找到(因为都在同一个地方)。
缺点:所有用户共享同一个目录,没有分层结构。
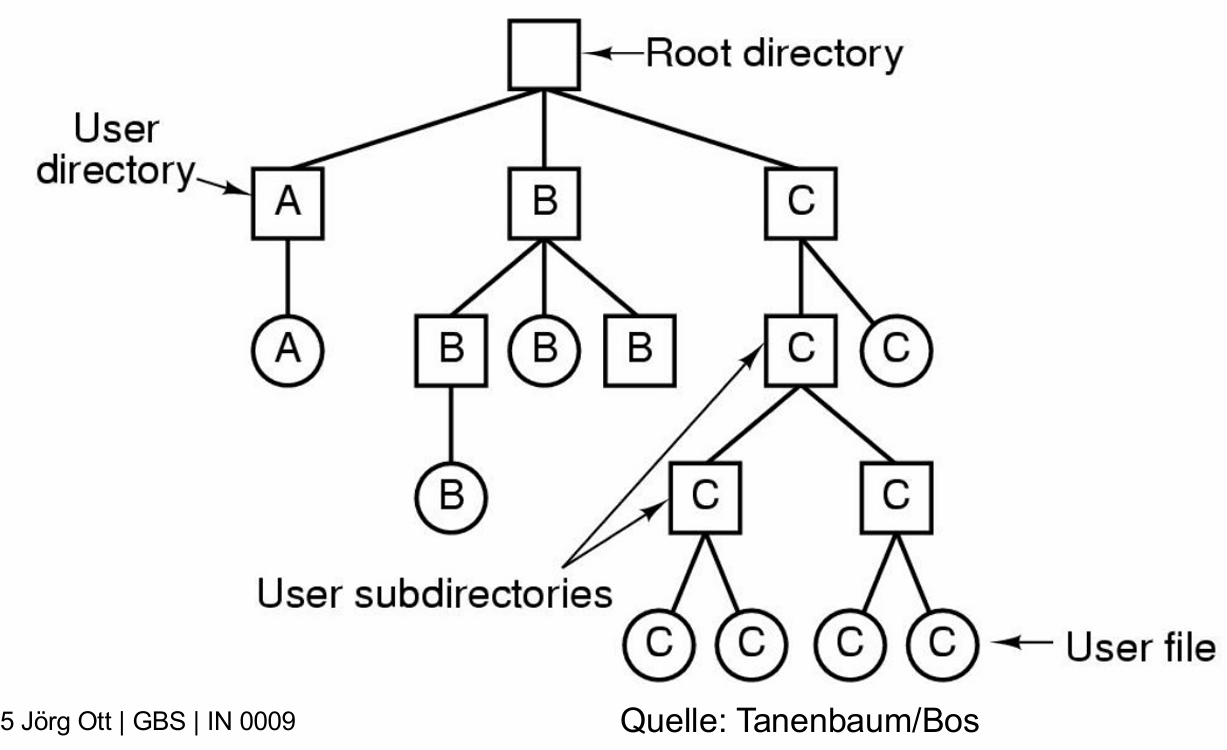
2. 层次型目录结构(Hierarchische Verzeichnisstrukturen)
这种会将相关的文件以分层方式组织在目录中,每个用户拥有自己专属的主目录,并可包含子目录。
# 路径名(Pfadnamen)
路径名是为了在树状结构的文件系统中为文件命名,一般分 3 种:
1. 绝对路径名(Absolute Pfadnamen)
路径从根目录(Root-Verzeichnis)开始,一直到目标文件。
注意:UNIX/Linux 中用 / ,Windows 中用 \ 。
例子:
/tum/git/gbs/uebungsbetrieb/ws18/09/c-files/mem.c
2. 相对路径名(Relative Pfadnamen)
路径是相对于当前工作目录(Current Working Directory)而言的。
比如当前路径是
/tum/git/gbs/uebungsbetrieb/ws18/09
的时候,就可以这样引用文件:
blatt09.pdf
或者
c-files/mem.c
3. 特殊路径
. 表示当前目录, .. 表示上一级目录。
例子:
假设当前路径是
ws18/09/
可以用
cp ../08/gbsuebung.cls .
# 从当前目录的上一级目录中的 08 子目录里,复制 gbsuebung.cls 文件到当前目录中
# 文件系统
从现在开始我们从实现角度(Implementierungs-Sicht)来了解文件系统:它内部是如何实现各种功能的。
# 文件系统布局(Dateisystem-Layout)
硬盘会被划分为多个分区(Partitionen),每个分区可以独立存储一个文件系统,彼此之间互不影响。
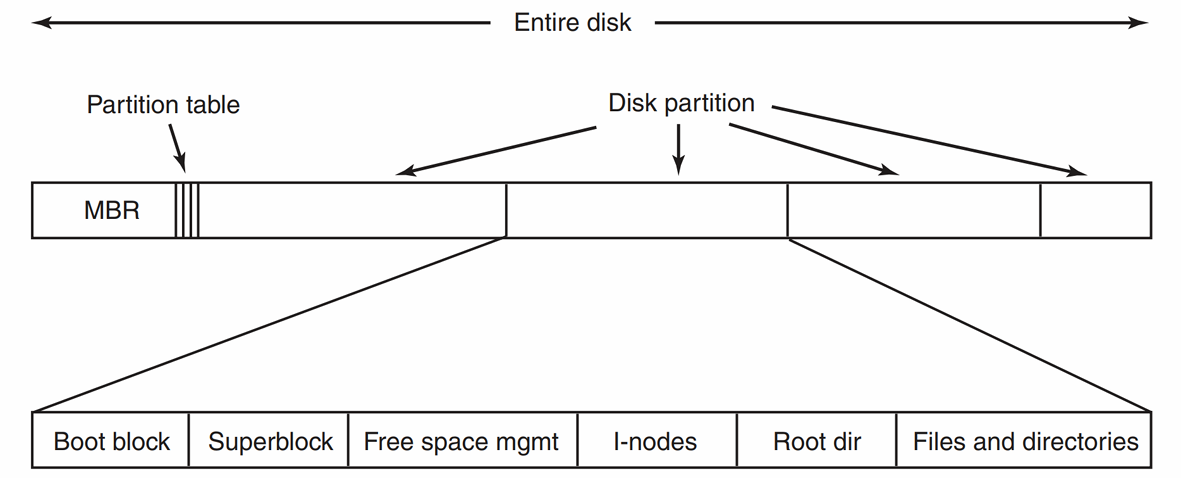
位于 Sektor 0 的是 ** 主引导记录(MBR,Master Boot Record) 。里面存储了一个 分区表(Partitions-Tabelle) **,用于纪录每个分区的起始和结束地址。
在启动电脑时(Booten),BIOS(或现代的 UEFI)会读取 MBR,执行 MBR 程序,然后根据分区表(Partitions-Tabelle)定位到活动分区(aktiven Partition),读取并执行该分区的第一个块 Boot Block 中的代码,引导操作系统加载。
每个分区内部的结构会随着文件系统的不同而变化。
上面图片里展示的是 UNIX/Linux 中文件系统的例子:
-
超级块(Superblock)存储关于整个文件系统的关键信息,包括 Magic Number(识别文件系统类型的标识), Anzahl der Blöcke, etc.
-
空闲块信息(Informationen über freie Blöcke)(上一章的内容)可以通过位图(Bitmap)或者指针链表(Pointer List)实现。
-
文件描述符集合(
i-nodes) -
文件和目录
# 文件的存储与实现方式(Implementierung von Dateien)
文件系统管理那些用于保存文件内容的磁盘块(Blöcke),但每个文件的数据都被分成多个块,系统怎么样可以知道这些块在哪儿呢?
以下是管理文件内容所用的三种主要实现方案:
# 连续分配(Contiguous Allocation)
文件被视为硬盘上一串连续的块,也就是说文件的所有数据块在物理磁盘上是挨在一起的(如下图)。
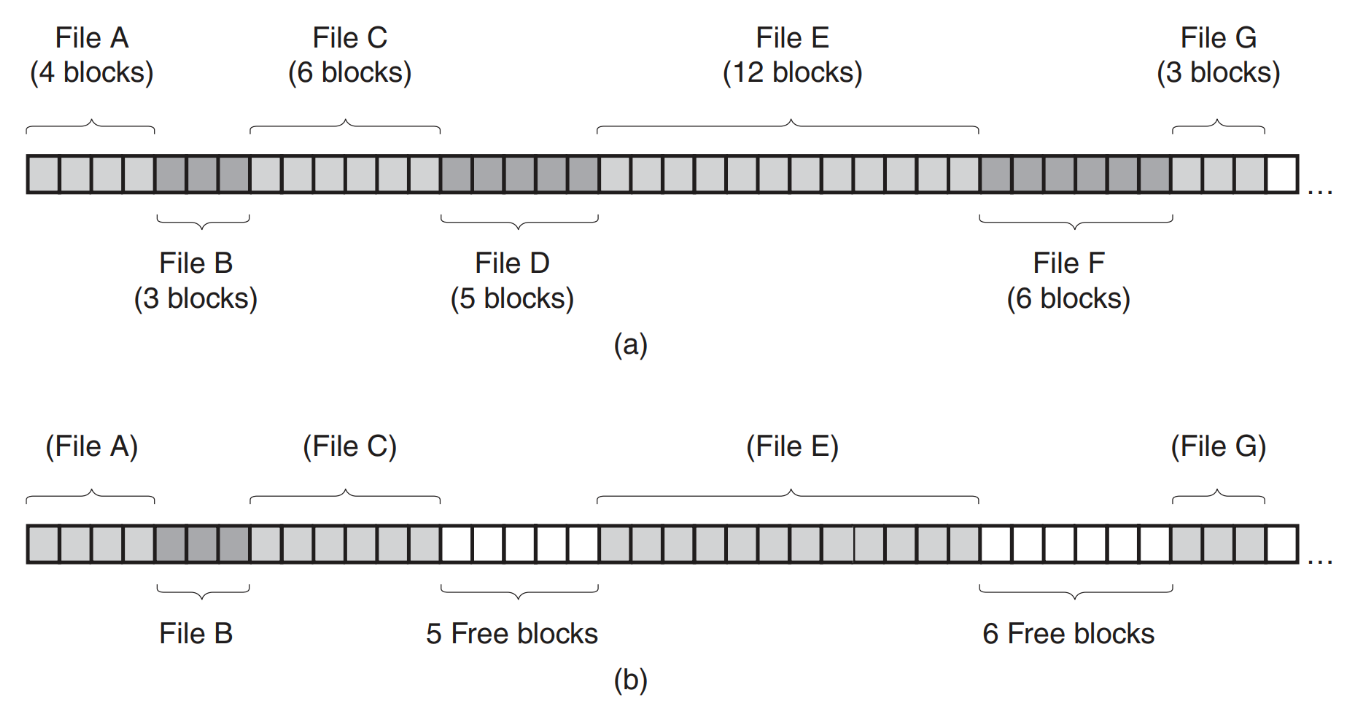
优点:
-
实现简单(Einfache Implementierung)
-
读取性能高(Lesen ist sehr performant)
由于数据连续,只需一次磁头定位就可以一次性把整个文件读完,非常高效。
缺点:
-
外部碎片问题(Externe Fragmentierung)
指随着文件的创建与删除(也就是外部原因)会产生很多小块,导致很难找到一大块连续空间给新文件。(如下图所示)
(interne Fragmentierung 指的是想 Buddy Algorithm 那样算法本身导致的碎片化。)
所以比较适合只读介质(Read-Only-Medien),比如说 CD-ROM,DVD,BluRay-Disks
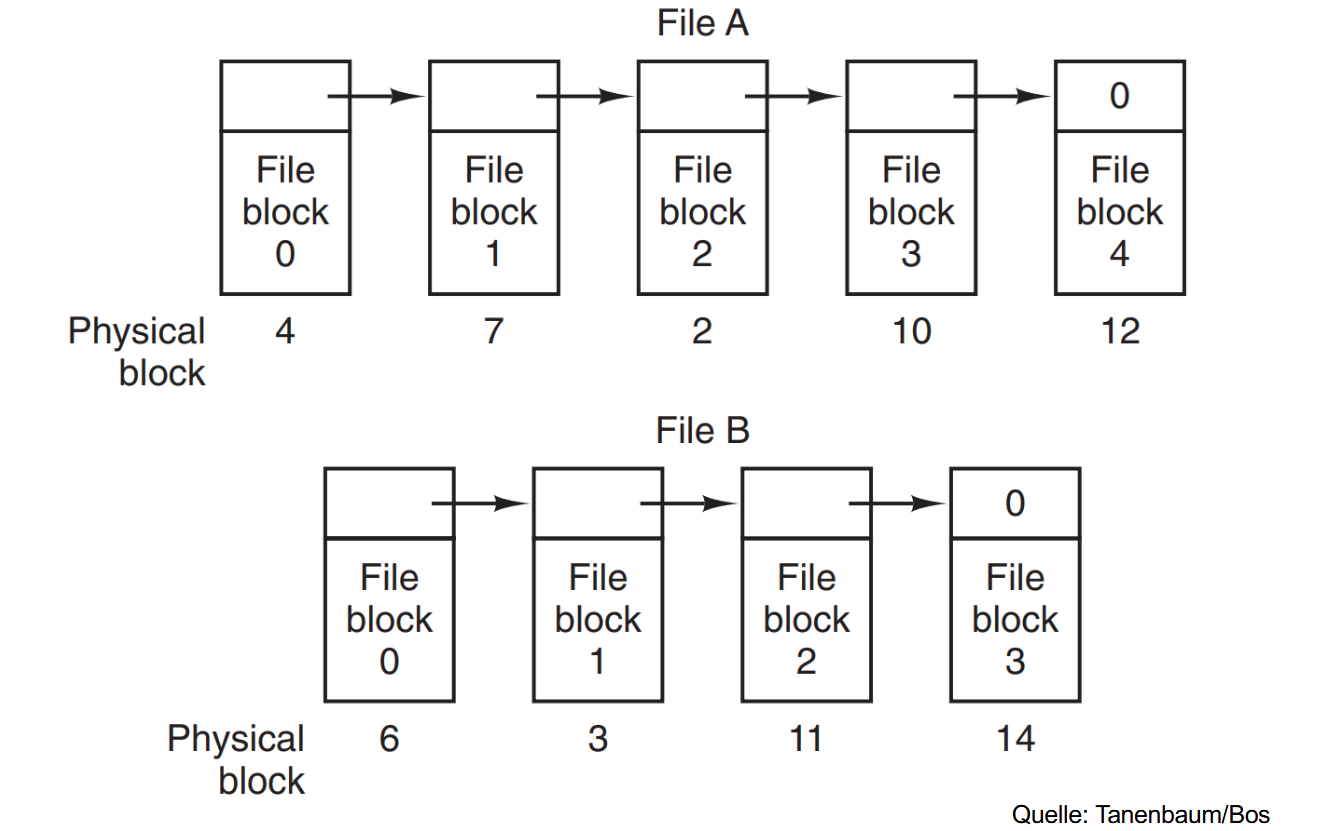
# 链式分配(Linked List Allocation)
使用一个链表管理所以文件使用的块,每个块的开头包含指向下一个块的指针。
优点:
-
不会浪费空间
不像连续分配那样需要一整段连续空闲区域,所有零散的空闲块都可以利用
缺点:
-
随机访问性能差(Niedrige Performance bei Random-Access)
因为如果要访问第 n 块,必须先读取完前 n-1 块。
-
每个块要占用一点空间存指针
导致可用空间不是标准的 2 的幂(keine 2er-Potenz)。
-
与操作系统块大小兼容性差
因为许多系统要求块大小是固定的(例如 512B、1024B、2048B 等),指针占了空间后可能导致不便于按块读取。
针对提到的这些问题我们可以在此基础上进行一点改良:
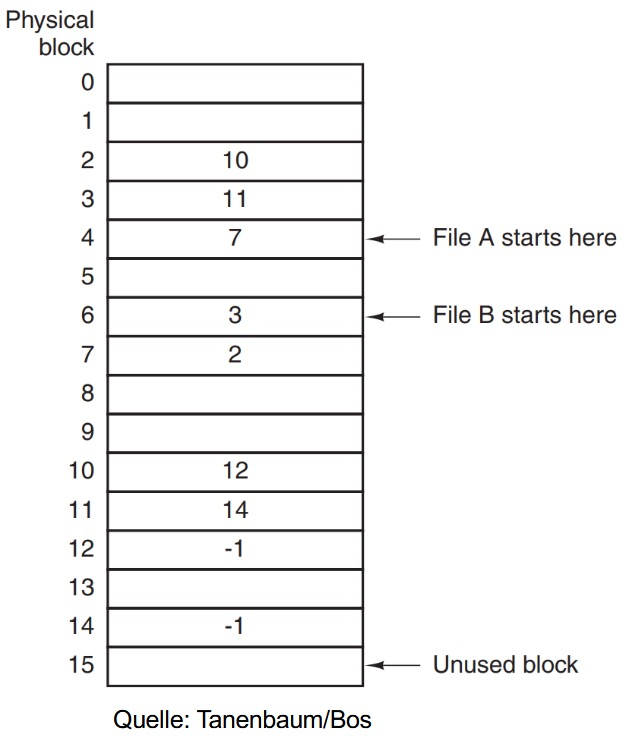
# FAT 文件分配表(Linked List Allocation mit File Allocation Table)
我们现在将所有指针集中存储在一张表中(FAT),放在主存(Hauptspeicher)中管理。
例子:
我们现在有 2 份文件:
A:4, 7, 2, 10, 12 (-1 = Ende der Liste)
B: 6, 3, 11, 14 (-1)
优点:
- 每个块不会浪费存储空间(kein Verschnitt)
- 随机访问(Random-Access)更快
- 只需要在内存中操作表即可
缺点:
- FAT 表必须常驻内存(RAM),会消耗大量内存。(磁盘空间越大 FAT 也越大)
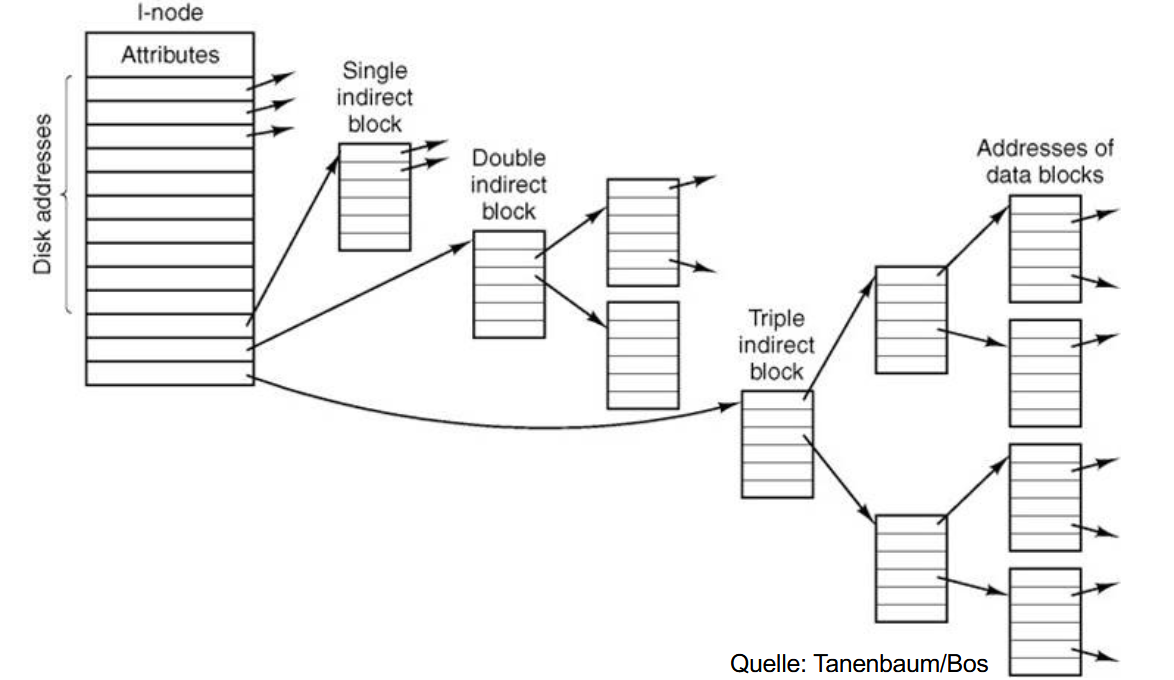
# i-nodes(索引节点)
每个文件都由一个 i-node 数据结构来表示,i-node 中会包含文件的元数据(Dateiattribute)以及磁盘块的地址( Adressen)。

优点:
-
内存占用低
因为只需将打开的文件的 i-node 加载到内存中。
-
可扩展性强
所需内存空间只与 “同时打开的文件数” 有关,而不是整个磁盘容量。
缺点:
- i-node 能存的地址数量是固定的
为了解决这个问题可以用多级间接地址:
比如说一级间接、二级间接、三级间接(Indirekte, doppelt indirekte und dreifach indirekte Blöcke),即最后的地址不是数据块,而是指向一个包含更多地址的 “块地址表”(即指针块)。
# 目录(Verzeichnissen)
操作系统需要通过解析路径名来找到硬盘上的实际文件位置。
一个目录其实就是一组目录项(Verzeichniseintrag,directory entry)的集合。当操作系统通过一个路径打开文件时,会挨个查找对应的目录项。
一个目录项会包含以下信息:
- 文件名
- 定位信息(Adress-Informationen, um die gesuchte Datei zu lokalisieren)
- 文件属性(Datei-Attribute)
(注意,目录项和文件是 2 个不同的东西。目录项实际上只是一条纪录,用于指向一个文件或者子目录,并不会存储文件内容(用于导航)。而文件是实际存储数据的对象)
# 文件属性的存储
有 2 种常见的方式:
1. 直接存储在目录项中:
每个目录项不仅包含文件名,还直接包含这个文件的属性信息。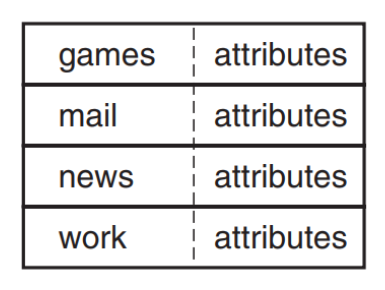
2. 存储在 i-nodes 中:
每个目录项只包含文件名以及一个指向 i-node 的引用(编号或指针),文件的所有属性都集中保存在 i-node 中。
# 文件名的存储
因为我们希望可以使用任意长度的文件名,所以需要考虑这些不同长度的文件名该怎么存储。
首先想到的便是
1. 固定文件名长度,比如说限制每份文件的文件名在 255 个字符以内。但是这样一来肯定需要给每份文件的文件名 255 个字符的位置,由于不是每份文件的名字都有这么长,很容易导致内存或者磁盘空间的浪费。
所以我们可以根据这个问题将这个方法改良一点:
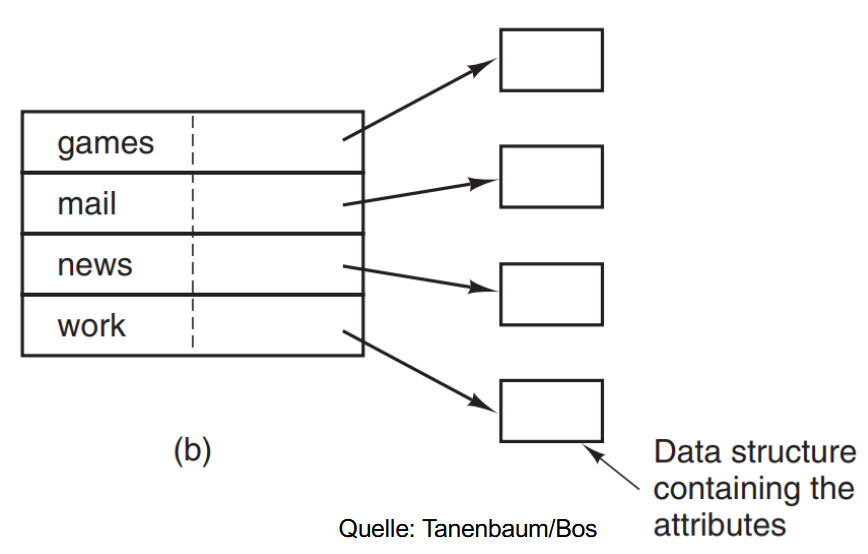
2. 允许文件使用任意长度的文件名,然后专门用一块空间记录当前文件名的长度。(如下图)

但是这种方法同样也有一个很大的问题:因为文件名长度的不同意,创建和删除文件容易导致存储空间碎片化。为了解决这个问题我们可以考虑将所有的文件名集中存储,也就是:
3. 只存储文件属性以及一个指向堆(Heap)里存储文件名位置的指针。(如下图)
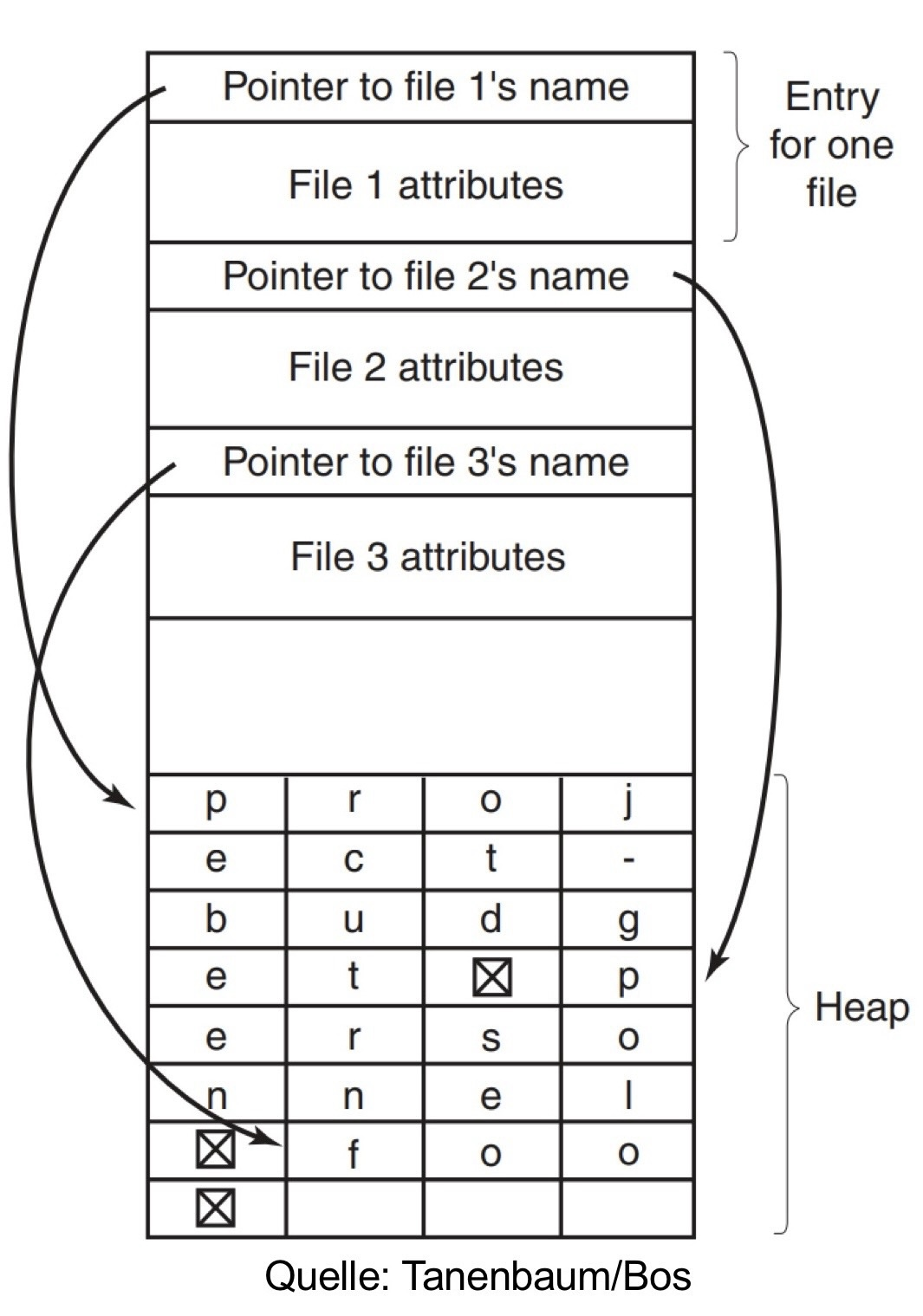
尽管已经改善很多了,但这个方案依旧不够完美:在包含大量条目的目录中查找文件会很慢(Suchen von Dateien in Verzeichnissen mit vielen Einträgen ist langsam)。所以我们可以
4. 在 3 的基础上引入哈希表来提高索引效率:
在每个目录中使用一个哈希表,通过对文件名进行哈希计算来得到目录项的索引。目录项中的哈希冲突(Kollisionen)则通过链表来处理。
# 链接(Links)
为了让(不同)用户在不同路径下可以打开同一份文件,我们需要引入链接这个机制。
链接分为 2 种:
-
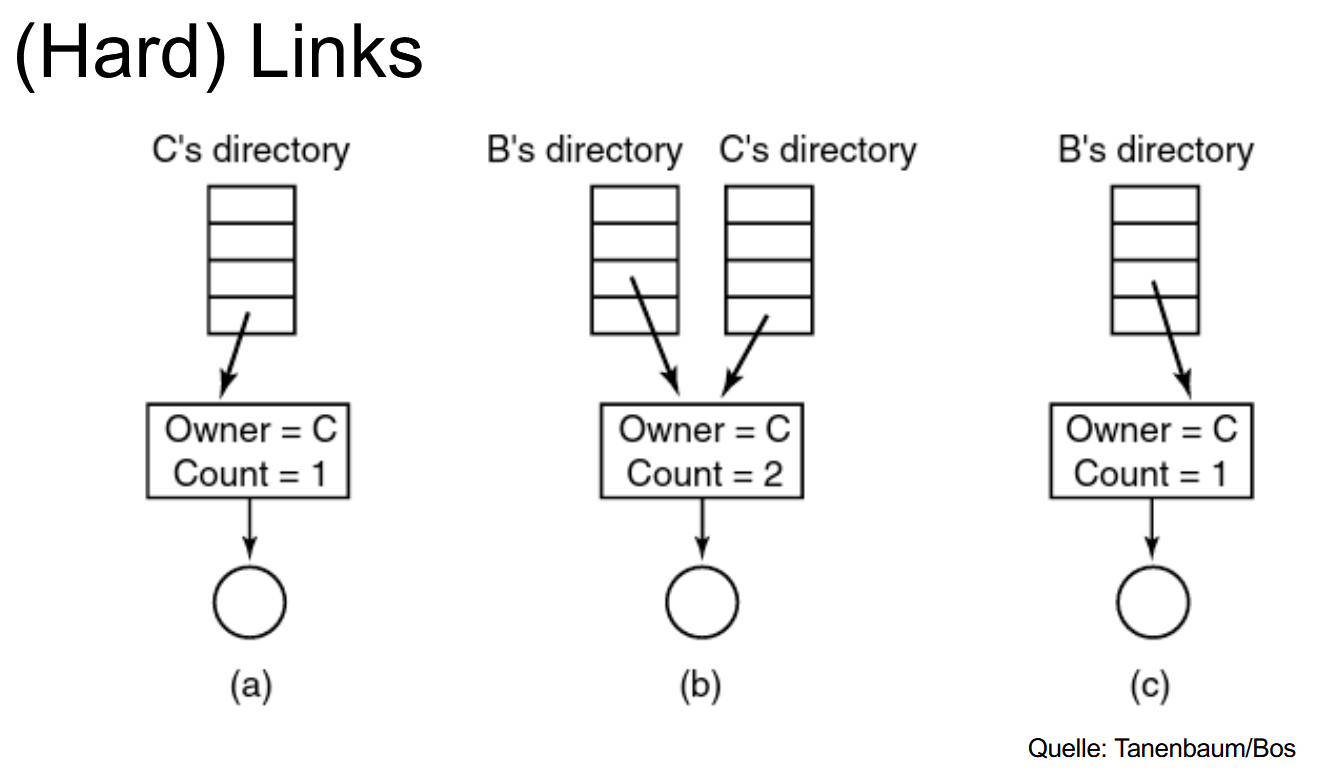
硬链接(Hard Links)目录项不是直接指向文件数据,而是指向 i-node,允许多个目录项指向同一个 i-node。注意,在硬链接里没有 “主链接” 或 “次链接” 的区别,所有硬链接是平等的。每个 i-node 会记录引用计数(ref count),当引用计数归零时,说明没有目录再指向它,就可以删除这个文件了。
(这也解释了 UNIX 删除命令叫 unlink (),因为它实际上是取消一个目录项到 i-node 的链接,而不是马上删除文件。)
-
软链接/符号链接(Symbolic Links)
创建一个特殊类型的文件,里面保存的是目标文件的路径名。
软链接类似于 Windows 里的快捷方式,但并不完全一样。软连接是文件系统级别支持,而快捷方式则是应用层支持。这意味着系统层面会自动解析软链接,但是 Windows 里的快捷方式需要 Shell 或资源管理器解析。
# 日志文件系统(Journaling-Dateisysteme)
主要是为了保证系统崩溃后的数据一致性,类似于 Datenbank 里的 Transaktionsverwaltung。
在 UNIX 下删除一个文件需要 3 个步骤:
- 从目录中移除文件的目录项(Entferne die Datei aus ihrem Verzeichnis)
- 将文件对应的 i-node 释放(Gib den i-node in den Pool der freien i-nodes frei)
- 将文件占用的磁盘数据块标记为 “可用”(Markiere alle von der Datei belegten Festplatten Blöcke als frei)
但如果在某一步结束后系统发生了崩溃,就会导致很严重的问题,比如说数据丢失或者是空间泄露。
所以我们需要 ** 日志文件系统(Journaling-Dateisysteme) ** 来预防这些问题:会先将所有对文件系统的更改操作记录在日志区域(Journal)中,然后才实际执行。这样一来所有操作都可以从日志中恢复或重做,确保一致性。
具体操作流程:
-
首先创建一个日志条目,描述即将执行的三项操作。(Erstellen eines Log-Eintrags, der die drei Operationen beschreibt)
-
将该日志写入磁盘的日志区。(Speicherung in Journal auf der Platte)
然后需要重新读取日志内容以确认是否正确写入。
-
执行实际的 3 步操作。(Ausführen der drei Operationen)
-
每完成一步操作,都在磁盘上记录一次 “进度”,表示该操作已完成。(Abschluss jeder Operation auf der Platte vermerkt: Fortschrittsbericht)
-
三个操作都成功完成后,删除日志条目。
然后在系统重启或者发生崩溃后会进行以下操作:
- 首先检查日志内容。(Inspektion des Journals)
- 如果发现某个操作没执行完,那么会重新执行所有操作。
只不过这些都一个共同的前提:所有操作必须是 ** 幂等的(idempotent) **,即进行 1 次操作与进行 n 次(相同的)操作得到的结果是一样的。
例子:
-
将一块 Block 标记成 frei:是 idempotent 的。
-
把空闲块简单地加到 “空闲块列表末尾”:不是 idempotent 的,需要改成
先检查一下块 n 是否已经在空闲列表中,如果没有,再加入。
还有一个办法也可以提高文件系统的可靠性(Erhöhung der Zuverlässigkeit):把多个操作包装成一个原子事务(atomaren Transaktion,即 ganz oder gar nicht)。
# 虚拟文件系统(Virtual File System,VFS)
为了系统的兼容性需求(不同的操作系统和设备可能使用不同的文件系统格式)以及多样化的应用场景,一般的操作系统都会支持多种文件系统。
比如在 Windows 下,可以同时有 NTFS、FAT32、CD-ROM 等文件系统。
Windows 会将每个文件系统会被分配一个独立的盘符(如 C:、D:),而类 Unix 系统则是将所有文件系统整合到一个统一的层级结构中,对用户完全透明。
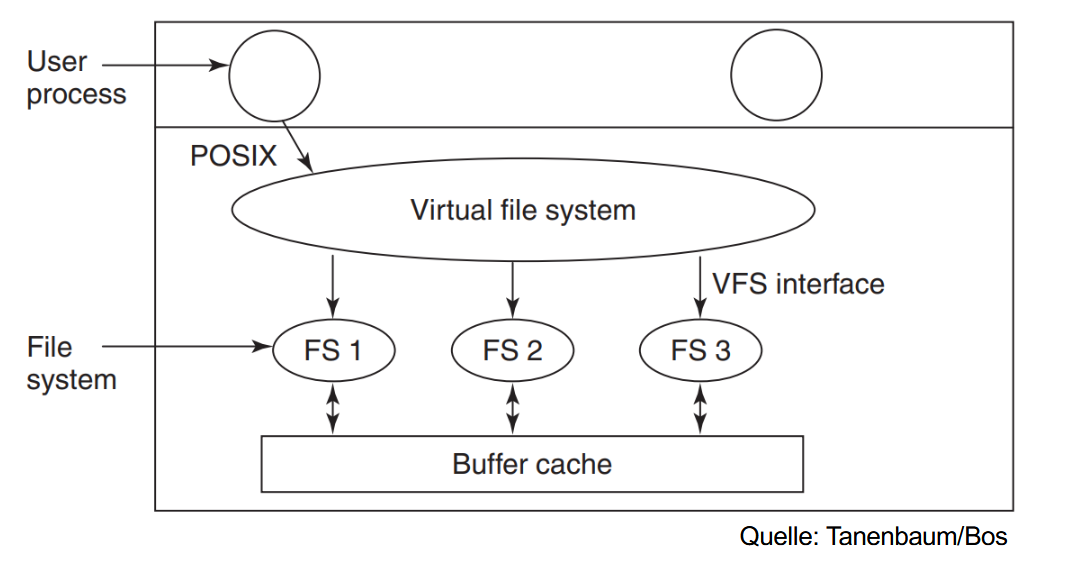
Unix 的这个整合是便通过 ** 虚拟文件系统(Virtual File System,VFS) ** 实现的。
VFS 负责提供一个(遵循 POSIX 标准的)统一的接口(比如 open``read``write``lseek ),用于支持在一个本地系统中接入多种不同的文件系统。
图示:
# 优化策略(Optimierung)
# Buffer Cache(缓冲区缓存)
(这部分 ERA 的 Cache 那一章会详细讲。)
文件系统使用内存中的一部分作为缓存区域,来暂存磁盘上的数据块。
对于读的操作的处理流程:
- 先检查所需的数据块是否已经在缓存中?如果是,就跳到步骤 3
- 如果不在缓存中:就从磁盘读取这个块,并加载到缓存中
- 返回这个数据块的内容给调用者(用户进程)
当缓存空间不够时也需要替换策略(Ersetzungsstrategie)。
进行写的操作时数据会先写入缓存区,不一定立刻写入磁盘。在 Unix 中可以使用 sync 命令手动将缓存区内容写入磁盘,不过系统自己也会会周期性自动执行(例如每 30 秒由 update 守护进程(daemon)完成)。Windows 采用的则是 Write-thru Cache,即写操作会立即同步到磁盘。
# 预读(Read-Ahead)
预读指的是提前把即将需要的数据块加载到缓存中,以此来提高读取性能。
可以
-
简单预测,或者
即假设用户会按顺序进行读取,比如说在用户请求读取某个文件的第 k 块时,就先检查第 k+1 块是否已在缓存中。如果不在缓存,就提前加载第 k+1 块。
-
结合结合文件的访问历史进行预测
给文件设置一个属性,记录它是否是被顺序读取。如果确认是顺序访问,才启用 Read-Ahead。
# 减少磁盘读写头的移动
-
尽量让同一文件的块物理上靠得更近
比如存储在同一个磁柱(Zylinder)上的 Blöcken 里。
-
块组分配(Verwaltung von Blöcken in Gruppen)
不按单个块分配,而是每次分配 2 个或 4 个块。这样可以隐式地提高局部性(Lokalität)。
-
i-node 结构不要都集中在分区开头(i-nodes nicht (nur) am Anfang der Partition)
# 碎片整理(Defragmentierung)
将文件的所有块重新排列,使它们尽可能连续,提高访问效率。(Neugruppierung der Blöcke der Dateien auf der Festplatte)
# 例子
# Linux 的 ext2
ext2 会将硬盘分区划分为 “块组” 结构(Aufteilung der Festplatten-Partition in Block-Gruppen)。
Block 0 是预留给系统启动用的(System-Bootup-Vorgang)。
而其余的所有 Block-Gruppen 都包含以下信息:
-
超级块(Superblock):包含有关文件系统布局的信息,比如说 i-node 和数据块的总数、空闲块列表的指针等。
(Anzahl der i-nodes und Blöcke, Pointer zur Liste mit freien Blöcken, etc.)
-
组描述符表(Gruppen-Deskriptor-Tabelle):包含这个块组的信息,比如说 Bitmap 的位置、空闲的 i-node 和数据块的数量、目录的数量等。
(Position der Bitmaps, Anzahl freie i-nodes und Blöcke, Anzahl der Verzeichnisse)
-
两个 **
位图(Bitmaps)**:每个 Bitmap 都是一个 Block 的大小,记录空闲块以及 i-nodes。通过这个 Bitmap 可以找到空闲的块以及 i-nodes。
-
i-nodes -
Datenblöcke
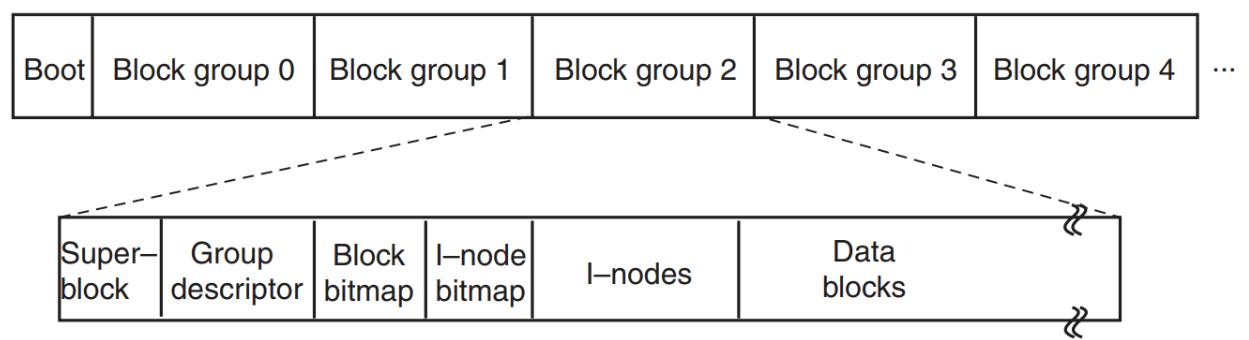
(这些 Block groups 都是 ext2 管理的空间)
ext2 中打开文件时,系统会在目录里查找该文件的 i-node 信息:
-
首先从目录条目(Verzeichniseintrag)中获取 i-node 编号(i-node-Nummer),通过该编号可以在硬盘上的 i-node 表中找到该文件的 i-node,并将其加载到内存中。
-
然后 i-node 会被写入内存中的 i-node 表。
i-node 表包含了所有已打开的文件和目录的 i-nodes。
目录文件结构图示:
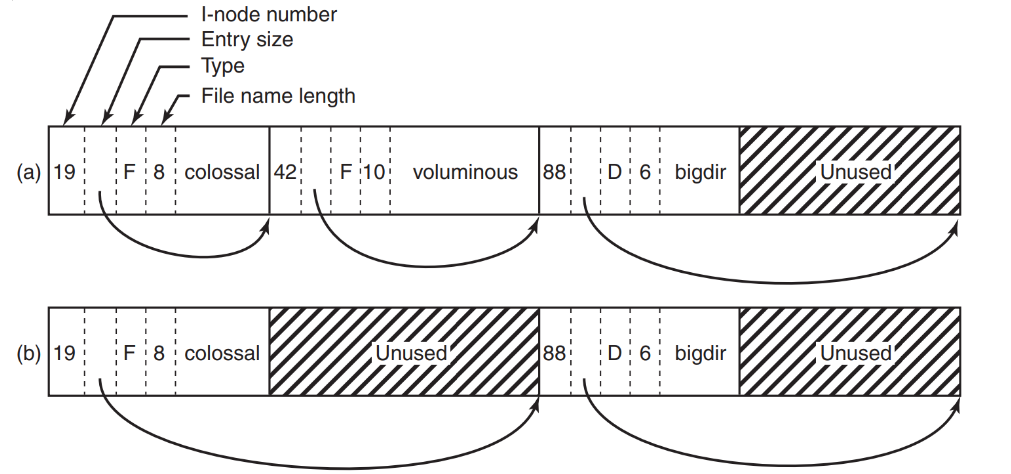
# Linux 的 ext4
ext4 则是在 ext2 的基础上加了 journaling 日志机制。这里的日志是一个文件,它会通过一个环形缓冲区(ring buffer)来实现。日志由一个独立于文件系统的层管理,叫做 Journaling Block Device(JBD) 。
JBD 中支持以下几种数据结构:
-
日志记录(Log-Eintrag (Log Record))
描述低等级的修改操作。
Beschreibt eine Low-level-Dateisystem-Operation, die einen Block modifiziert.
-
原子操作句柄(Atomic Operation Handle)
会将一组相关的日志记录组合在一起,并原子性地执行。(Gruppiert mehrere zusammengehörige Log-Einträge und führt sie atomar aus)
比如说
write一般会涉及修改 i-node、数据块、空闲块列表等信息,而这些操作应当作为一个整体 原子性执行(atomar als Einheit ausgeführt werden)。 -
事务(Transaktionen)
JBD 会将多个原子操作作为事务处理。一组日志记录只有在相关的所有实际写入操作都完成后,才能从日志中移除。
(这些内容在之前的日志文件系统(Journaling-Dateisysteme)都讲过,跟 Datenbank 里的也差不多。)
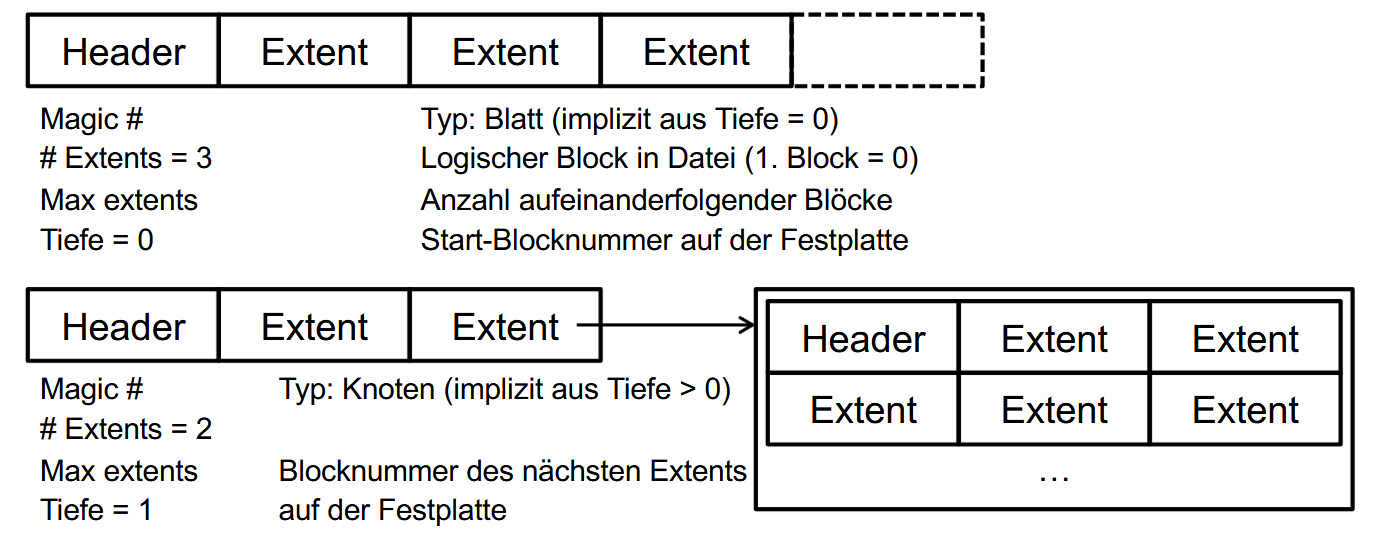
ext4 同样改进了将块映射到文件的方式:在 ext2/3 中都是使用指针指向单个块(Direkte und ein-/zwei-/dreifach indirekte Blöcke),这样一来如果块的数量过多可能会导致指针数量也过多。所以 ext4 采用的是 ** Extents **:
Instead of storing a list of every individual block which makes up the file, the idea is to store just the address of the first and last block of each continuous range of blocks. These continuous ranges of data blocks (and the pairs of numbers which represent them) are called extents.
图示: